
はじめに
解説動画を作るときのスライドを、NotebookLMの「スライド資料」機能(英語版UIでは「Slide Deck」)で生成できないかを試している。何を渡してどう指示するかで生成結果が大きく変わるので、同じ動画原稿を題材に入力方式を4パターン変えて比較 した。題材は「AI自動化はどこまで任せるべきか〜適性スペクトラムの考え方〜」のスライド1〜14。
検証した 4 パターンは次のとおり。
| パターン | 入力ソース | 図解種別の指定 | 装飾制限 |
|---|---|---|---|
| 1 | 簡素なスライド構成データ | 14 スライド分すべて明示 | あり |
| 2 | 詳細なスライド構成データ | 14 スライド分すべて明示 | なし |
| 3 | 詳細なスライド構成データ + 自然文の台本 | 14 スライド分すべて明示 | なし |
| 4 | 自然文の台本のみ | 指定なし | なし |
ソース(Part A)は NotebookLM の「ソースを追加」からアップロードする入力データで、カスタムプロンプト(Part B)は「スライド資料」の生成時にプロンプト欄に入力する指示テキスト。各パターンではこの 2 つの内容と組み合わせを変えている。
パターン1〜3 は NotebookLM に「書いた通りに出させる」方式、パターン4 だけが「NotebookLM に構造判断を任せる」方式、と捉えると違いが分かりやすい。
結論
全パターンを通して分かったのは、NotebookLM はスライドの枚数も各スライドの内容も指示通りに忠実に再現できる こと。これを前提にした上で、入力方式を変えるとビジュアル表現や情報密度がどう変わるかが本記事の本題になる。
結論から言えば、YouTube 解説動画のような「手軽にきれいなスライドを作成したい」用途では、パターン4(自然文の台本をそのまま入力する方式) が最も合っていた。以下がその理由と、私が採用している方針。
パターン4 を選んだ理由
NotebookLM の図解性能を最大限に引き出せるから。パターン4 は、NotebookLM 自身に要約・構造化と図解の組み立てを任せる方式。AI が台本を咀嚼してスライドに合った情報密度とレイアウトを自動で選ぶため、後述する図解種別の枠組みでは表現しきれないような自由度の高い図解が出てくる。「書いた通り」を再現させる他パターンとは違って、NotebookLM 本来の強みが一番よく出る使い方だ。
もう一つは、ビジュアル的におしゃれで綺麗に仕上がる こと。制約を絞った分、台本のトーンに合ったレイアウトや色使いが自然に選ばれ、解説動画の絵として映える。こうしたビジュアルの細かな調整をプロンプトで作り込むのは現実的ではないので、NotebookLM の判断に任せた方が結果も手間も良い。
動画用の台本をそのまま入力できるので 1 ファイル運用で済む、装飾制限(NO gradients のような否定形指示)を入れないので結果のブレが少ない、といった実務的な楽さもついてくる。
動画制作での方針
- ソースは自然文の台本 1 ファイルだけにする
- 台本に
## スライドN:のマーカーを入れて、スライドの区切りだけ明示する - カスタムプロンプトは枚数制御とトーン指示(
Professional, calm, data-drivenなど)に絞る - 装飾制限(
NO gradientsなどの否定形指示)は一切設けない
ただし、他パターンにも適した用途がある
パターン1〜3 は、カスタムプロンプトで Hierarchical Pyramid(ピラミッド図)や Iceberg Diagram(氷山図)のように図解の種類を 14 スライド分すべて明示指定する方式で、指定通りに忠実に出てくる。社内資料や教材のように構成を厳密に固定したい用途では、この再現性の高さがそのまま強み になる。「書いた通り」が欲しいか「良きに計らってほしい」かで選び分ければよい。
各パターンの詳細
各パターンの末尾には入力したソース全文とカスタムプロンプト全文をたたみ込みで置いてある。同じ結果を試したい人はそこから展開するか、テキスト版をダウンロードしてほしい。
パターン1: 簡素なスライド構成データ + 装飾制限あり
スライド構成を簡素な箇条書きで記述し、カスタムプロンプトで細かな装飾制限(NO gradients / NO decorative borders / 60% visual / 40% text)を指示する方式。図解の種類は 14 スライド分すべて明示指定する(Hierarchical Pyramid, Iceberg Diagram など)。
シンプルで統一感のあるスライドを狙った方針だが、後の比較を見ると、装飾制限がかえって表現を硬くしてしまっている。
パターン1 の方針(要約)
- Part A(ソース)にスライドの構成を簡素な箇条書きで記述
- Part B(カスタムプロンプト)で 14 スライド分すべての図解種別を明示指定(
Hierarchical Pyramid,Iceberg Diagram,Hub & Spoke diagram等) - 装飾制限あり(
NO gradients/NO decorative borders/NO stock photos of people) - ビジュアル比率
60% visual / 40% textを指示 Maximum 5 bullets per slide. Max 30 words per slide.で情報量を制限
パターン1 のソースドキュメント(Part A・全文)
## スライド1: タイトル
タイトル: AI自動化はどこまで任せるべきか?
サブタイトル: 適性スペクトラムの考え方
## スライド2: 核心メッセージ
【キーメッセージ】
「AI化すべきかどうか」ではなく「どのレベルの自動化が最適か」
タスクの性質ごとに最適解が異なる
## スライド3: 適性スペクトラムの5段階
【図解: ピラミッド】
5層のピラミッド(下が最も自動化に適する):
頂点(レベル5): AI自動化が不適切(司法判断)
第2層(レベル4): 人間中心+AI支援(経営戦略)
第3層(レベル3): AI支援+HITL(医療画像診断)
第4層(レベル2): 高度自動化+監視(一次サポート)
底辺(レベル1): 完全自動化(請求書処理)
下から緑→黄→オレンジ→赤→濃い赤
## スライド4: 自動化向きと人間中心の対比
【図解: 対比図】
左「レベル1-2: 自動化が最適」(緑〜黄系):
- 構造化度が高い
- エラー許容度が高い
- フィードバックが速い
- 例: 請求書処理、スパムフィルタ
右「レベル4-5: 人間が主体」(オレンジ〜赤系):
- 暗黙知への依存が高い
- 責任帰属が重大
- 倫理的判断を含む
- 例: 司法判断、経営戦略
中央: レベル3がHITL最適ゾーン
## スライド5: セクションタイトル
タイトル: なぜこう考えたか
サブタイトル: 根拠となる発見
## スライド6: 地味な反復処理のROIが高い理由
【図解: 概念図】
中心: なぜ「地味な反復処理」のROIが高いか
放射状に4つの理由:
- 構造化度が高い
- エラー許容度が高い
- フィードバックが速い
- 検証が自動化できる
5変数が全て自動化に適した方向を向いている
## スライド7: AI生産性効果の実態
【図解: 氷山図】
水面上(見えるもの):
- ベンダー調査「55%速くなった」
- 華やかなデモと成功事例
水面下(見えないもの):
- 独立実験では19%遅くなった
- 知覚と現実に約40ptの乖離
- 95%のパイロットがP&L効果なし
- 組織全体では安定性低下
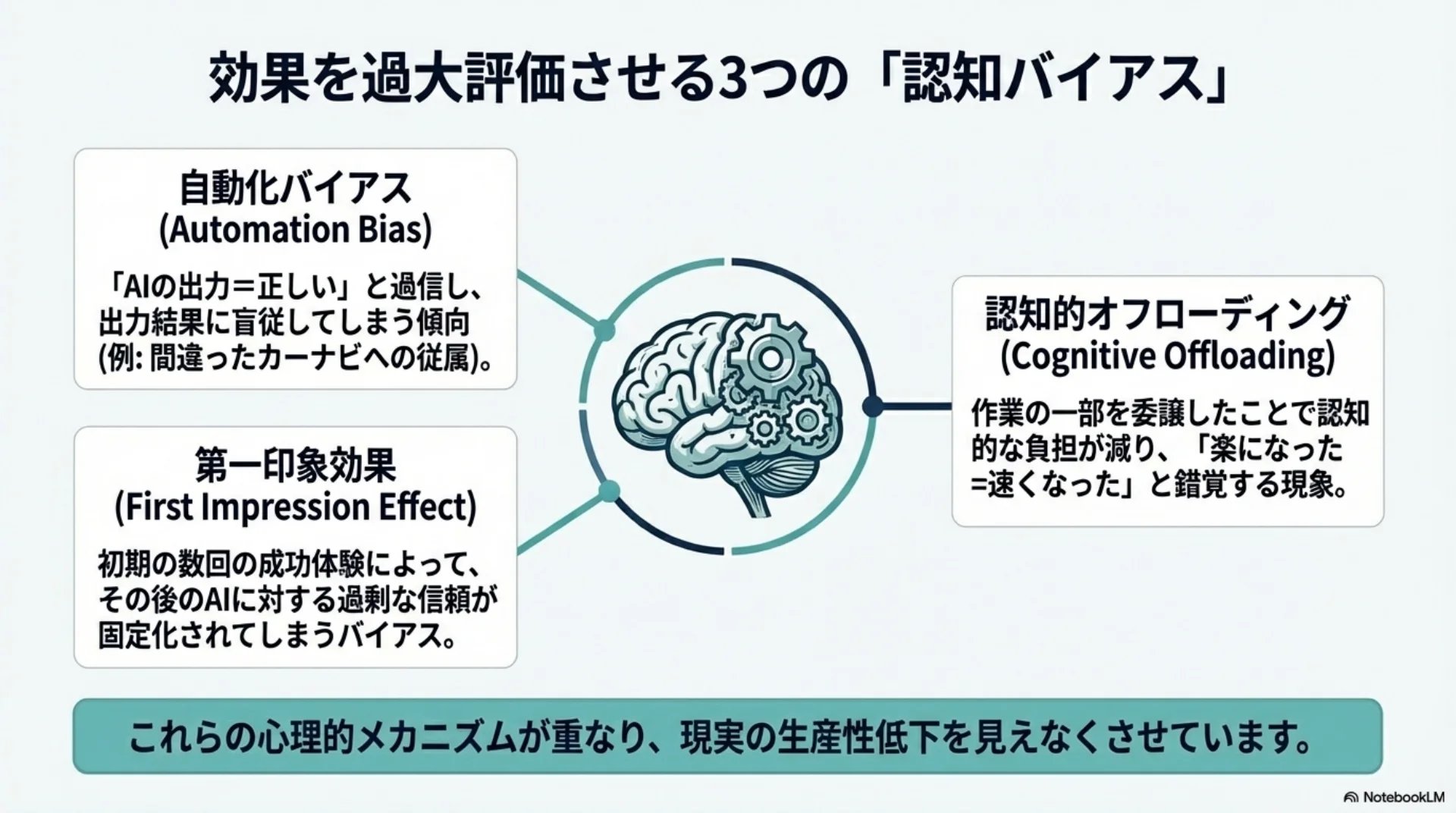
## スライド8: 認知バイアスの構造
【図解: 概念図】
中心: なぜ効果を過大に感じるか
放射状に3つのメカニズム:
- 自動化バイアス: 自動化結果に過度に依存
- 認知的オフローディング: 負荷軽減で効率向上と錯覚
- 第一印象効果: 初回の成功が過信を固定化
知覚と現実に約40ポイントの乖離が生じる
## スライド9: ハルシネーションの原理的限界
【キーメッセージ】
「ハルシネーションの完全排除は数学的に不可能」
真実性・情報保存・関連知識開示・最適性の4性質を同時に満たせない
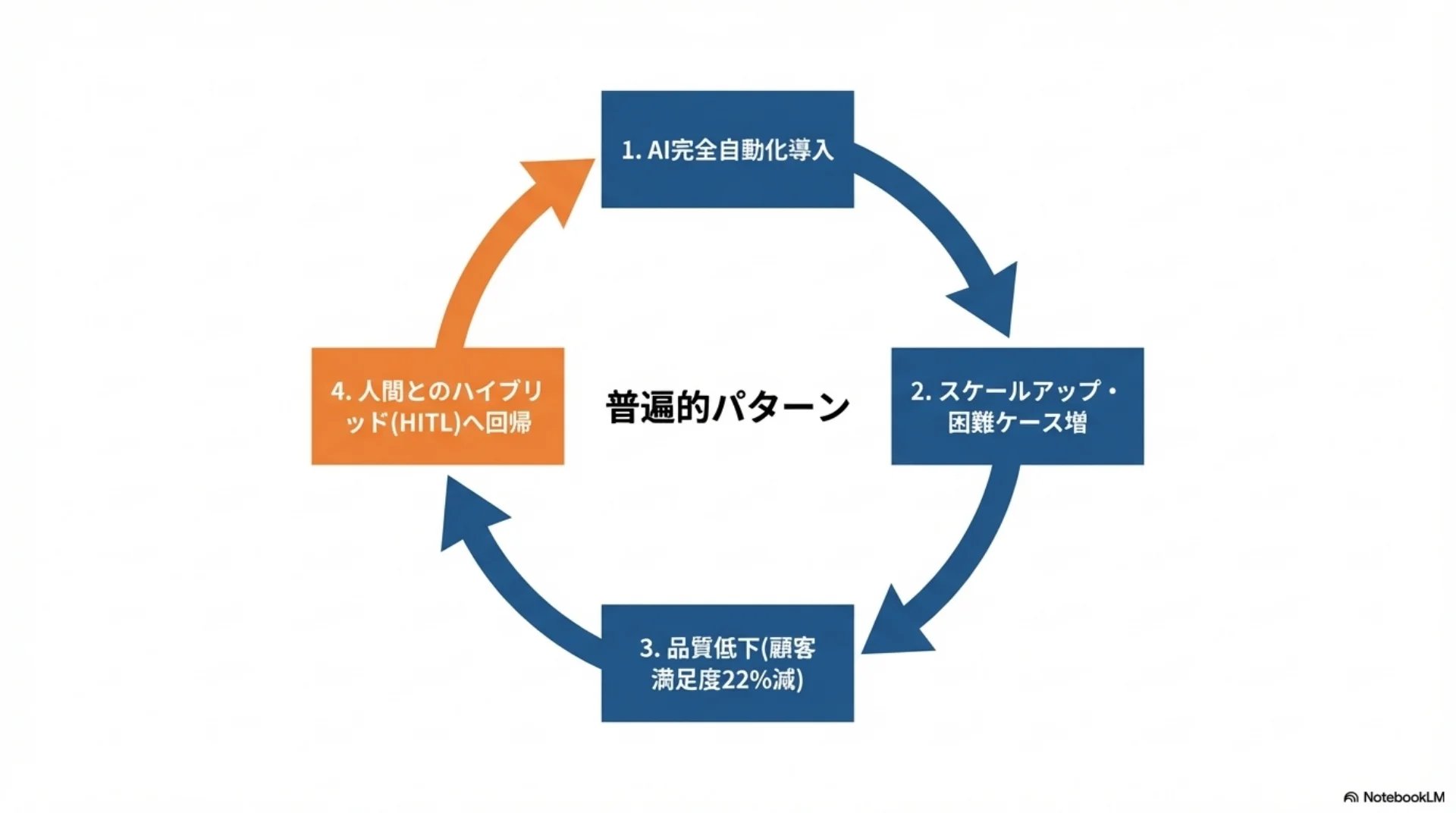
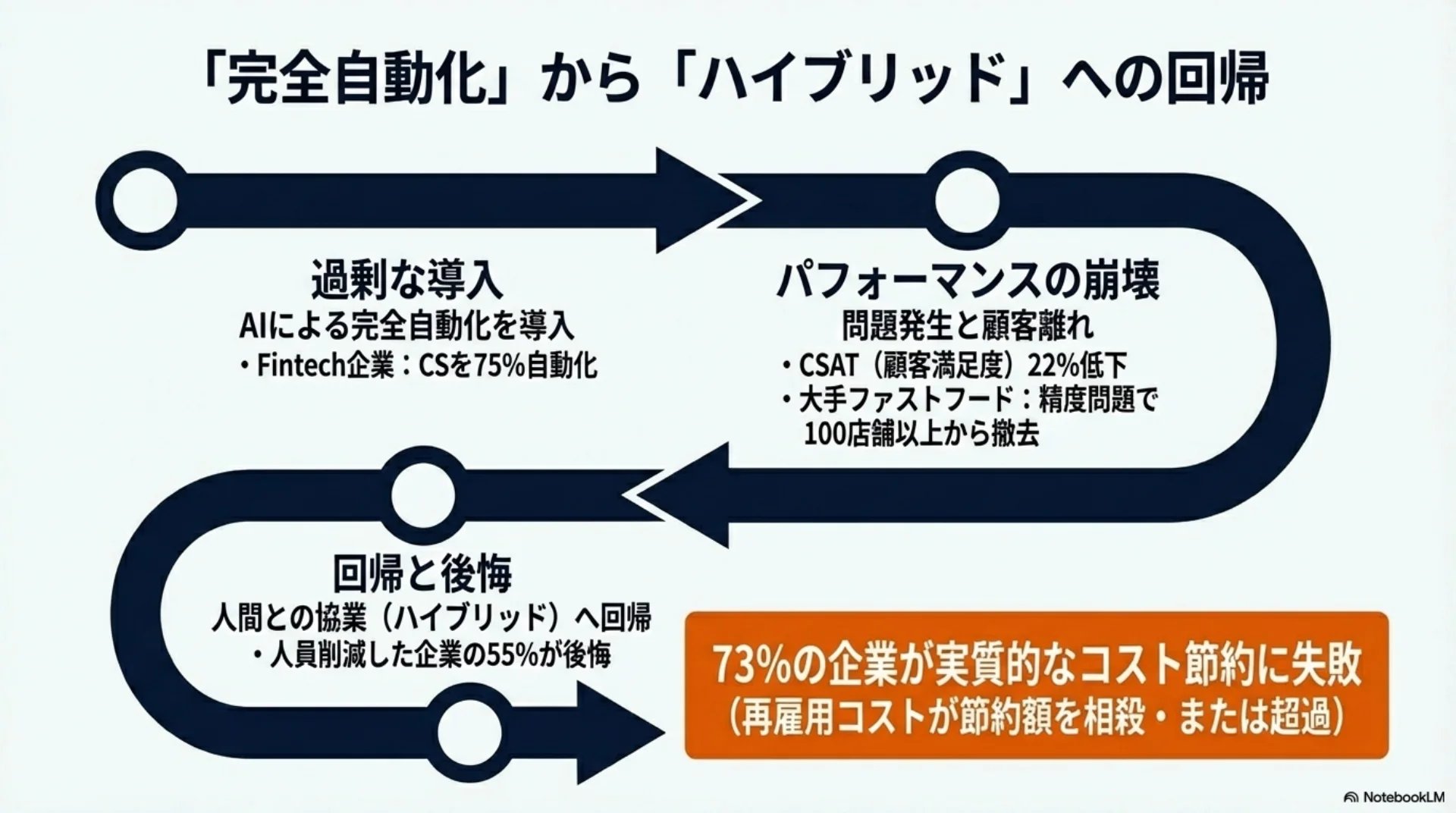
## スライド10: 完全自動化からハイブリッド回帰
【図解: 循環図】
時計回りに4段階:
1. AI完全自動化を導入
2. スケールアップで困難なケース増加
3. 品質低下が顕在化(顧客満足度22%低下)
4. 人間とのハイブリッドに回帰
完全自動化→ハイブリッド回帰の普遍的パターン
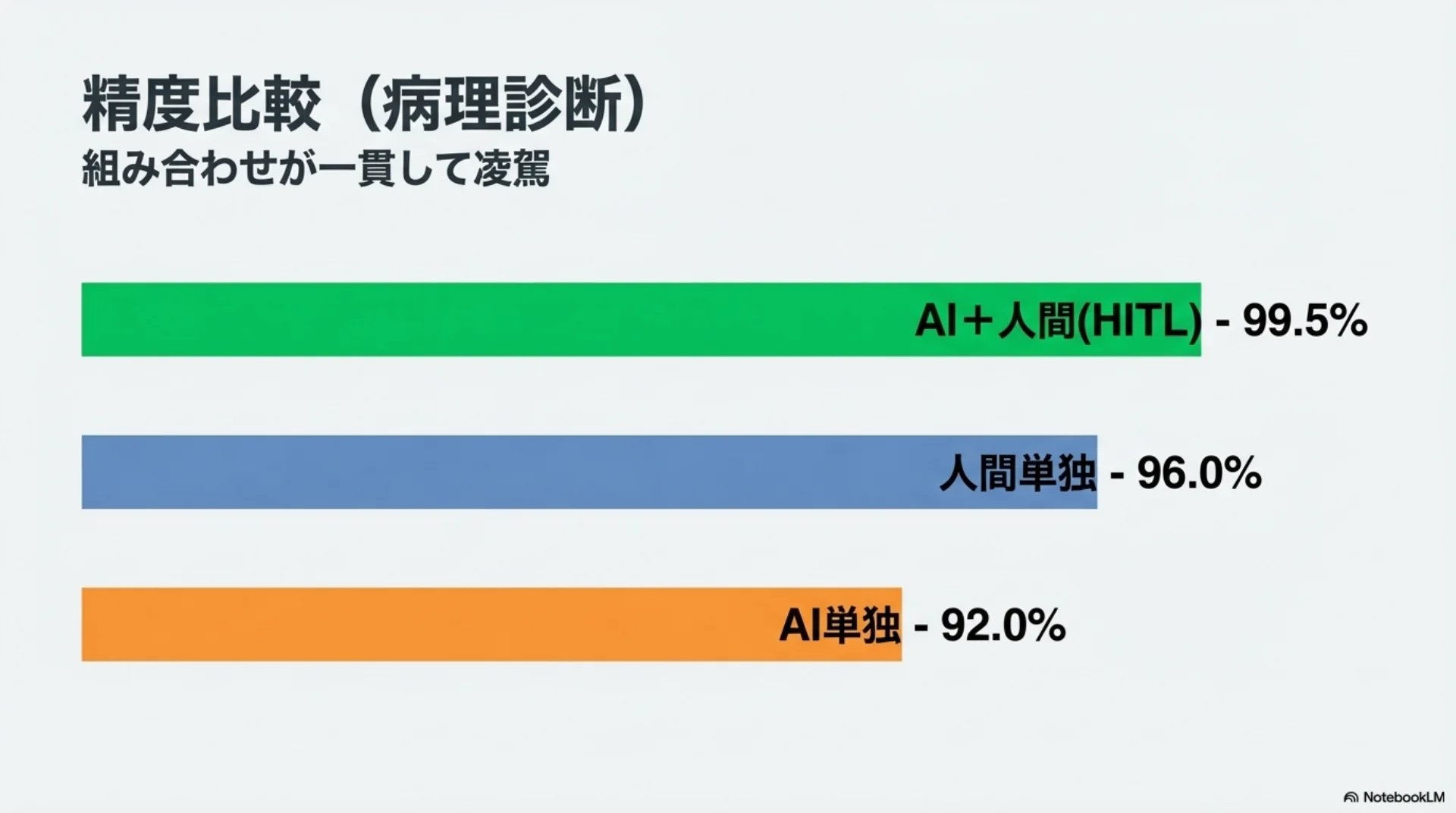
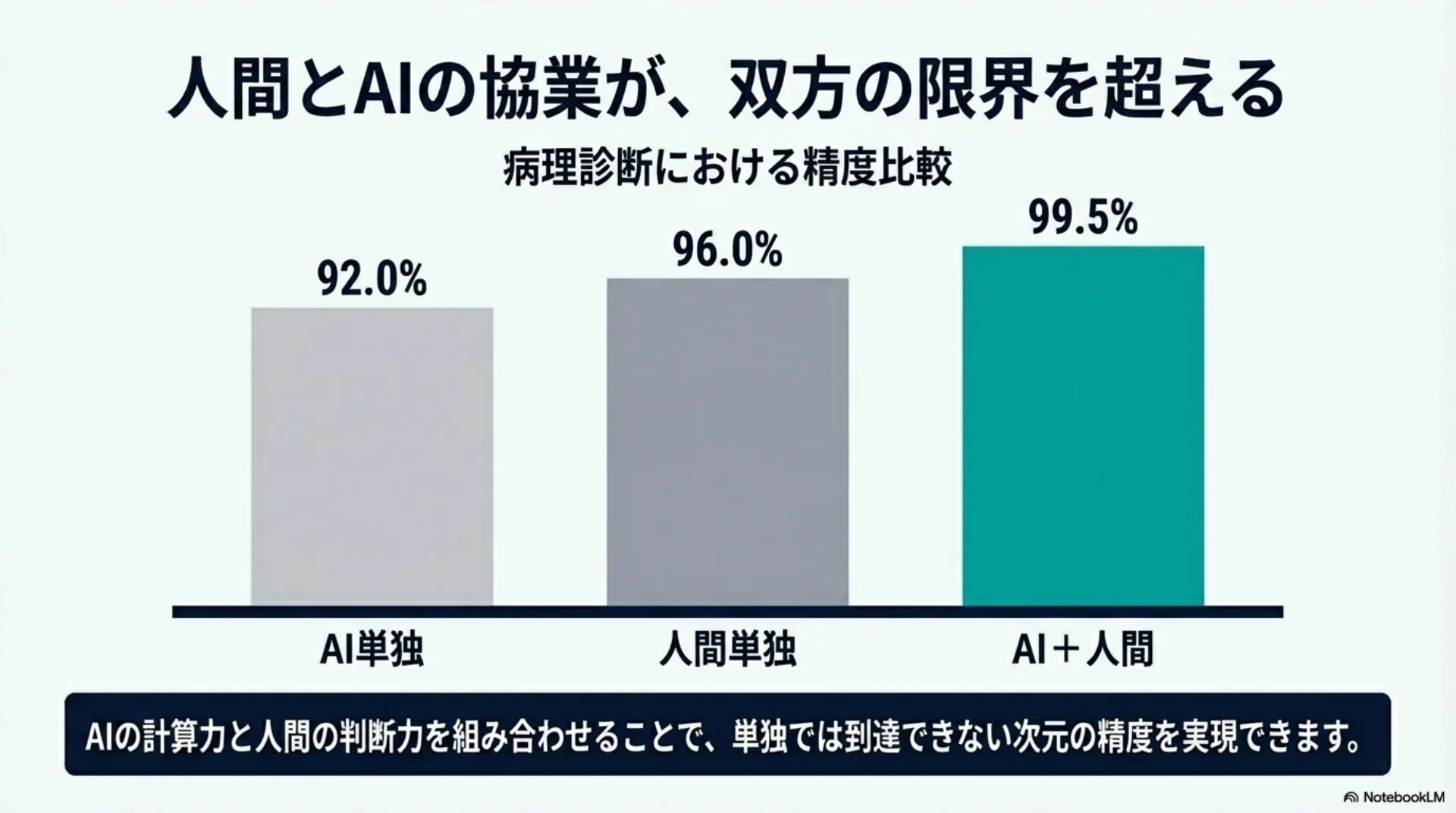
## スライド11: 精度比較(病理診断)
【図解: 横棒グラフ】
- AI+人間(HITL): 99.5%(緑、ハイライト)
- 人間単独: 96%(青)
- AI単独: 92%(オレンジ)
組み合わせが単独を一貫して上回る
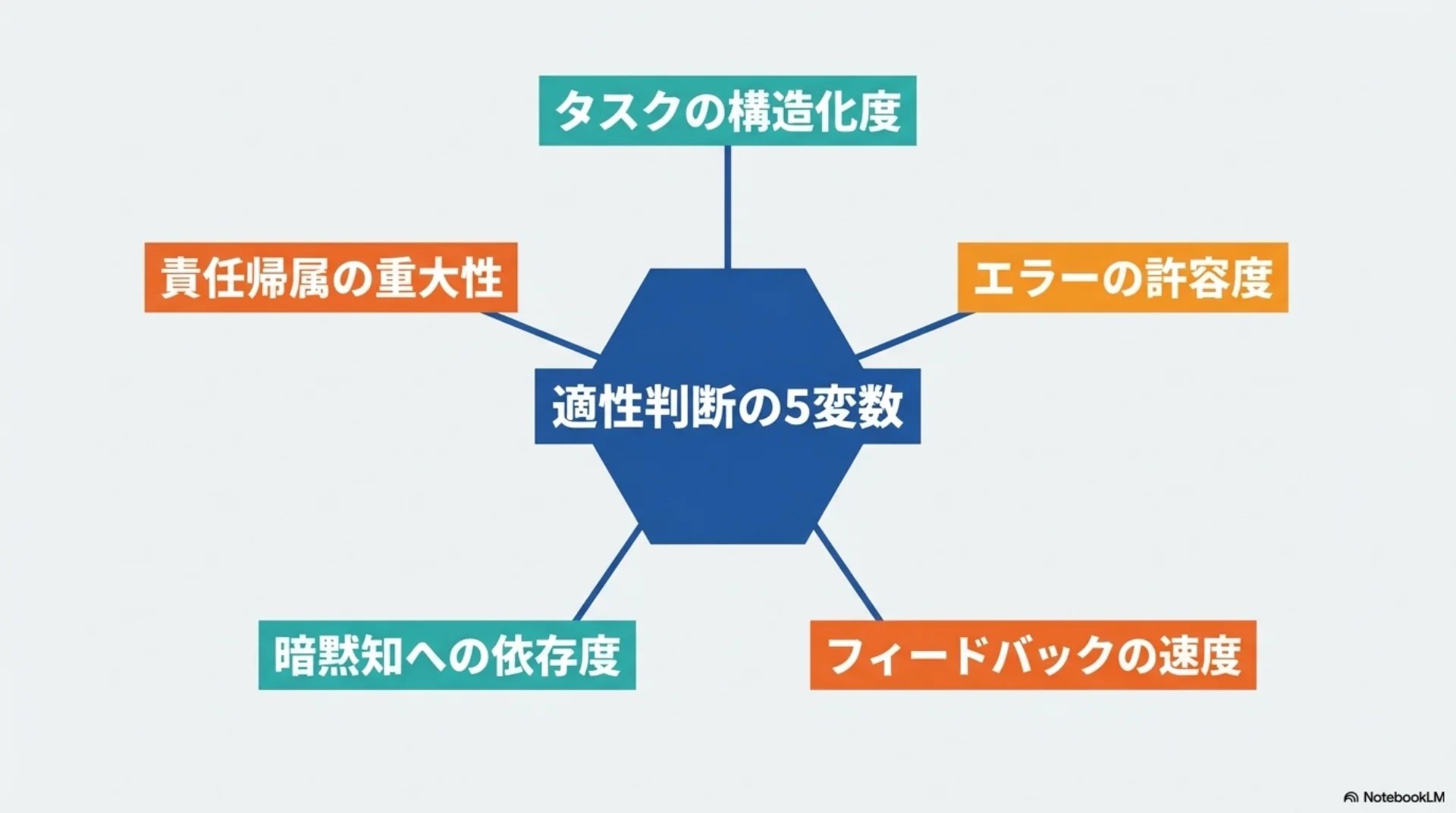
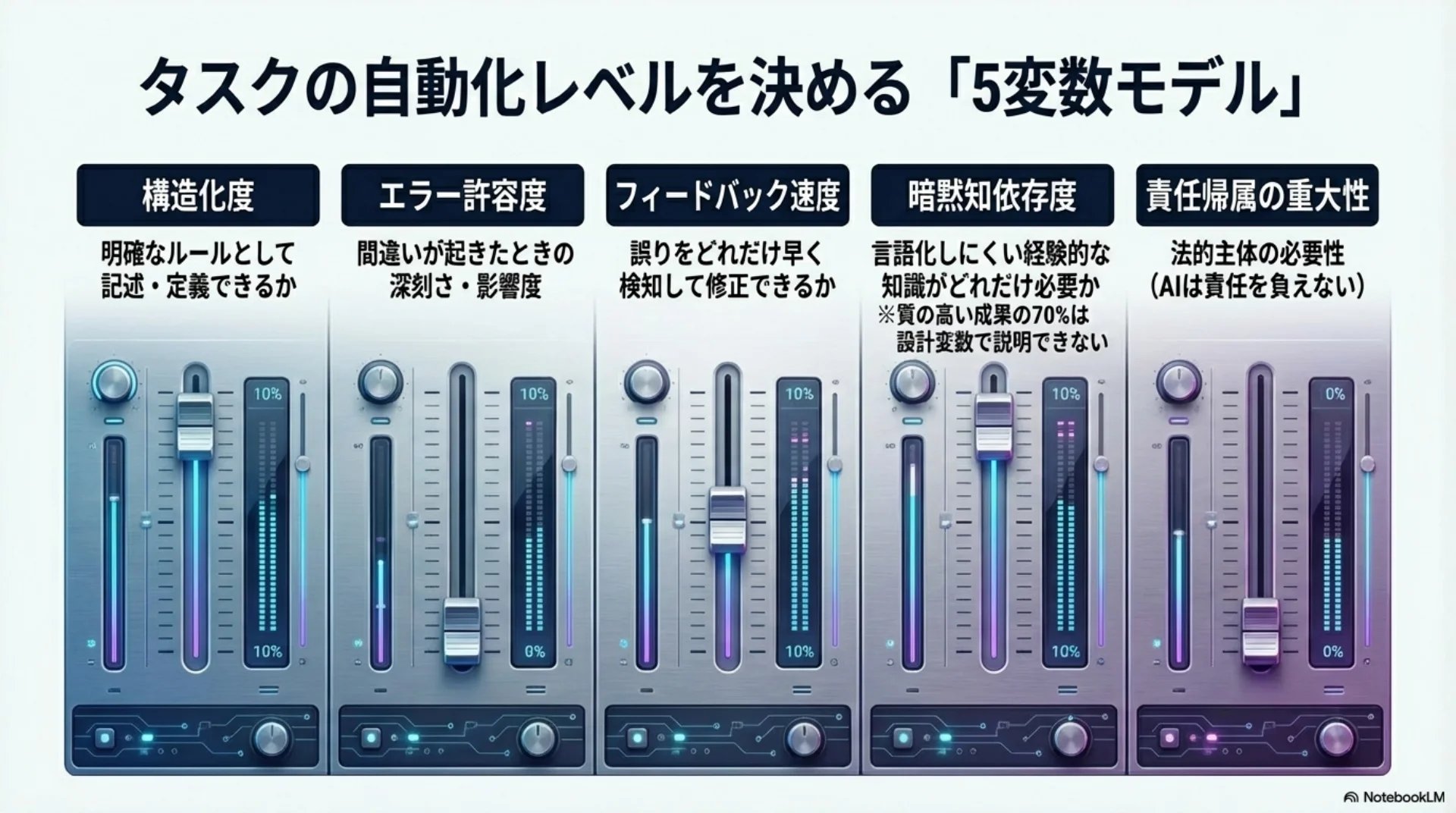
## スライド12: 5変数モデル
【図解: 概念図】
中心: 適性スペクトラムの判断基準
5つの放射状要素:
- タスクの構造化度
- エラーの許容度
- フィードバックの速度
- 暗黙知への依存度
- 責任帰属の重大性
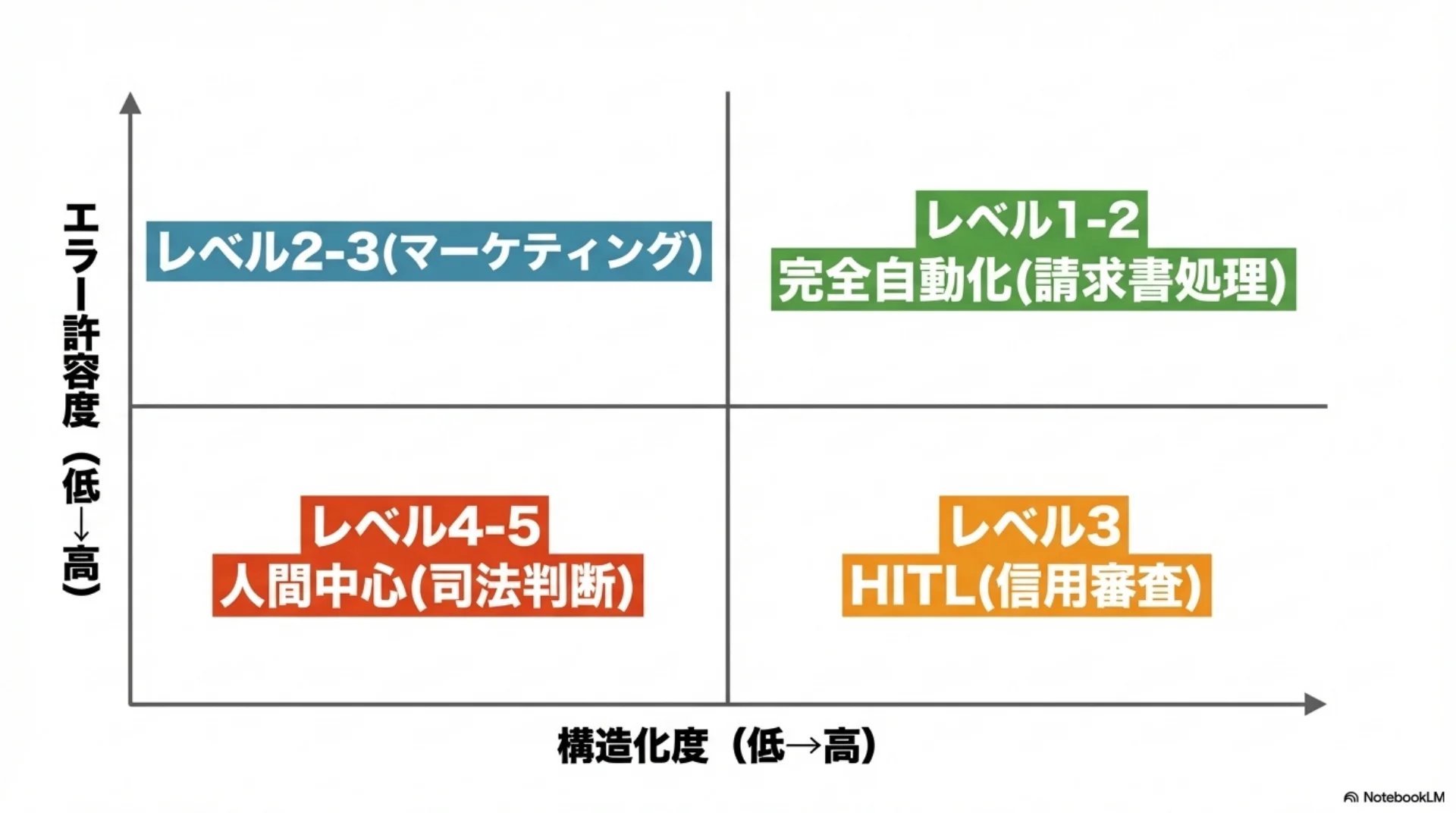
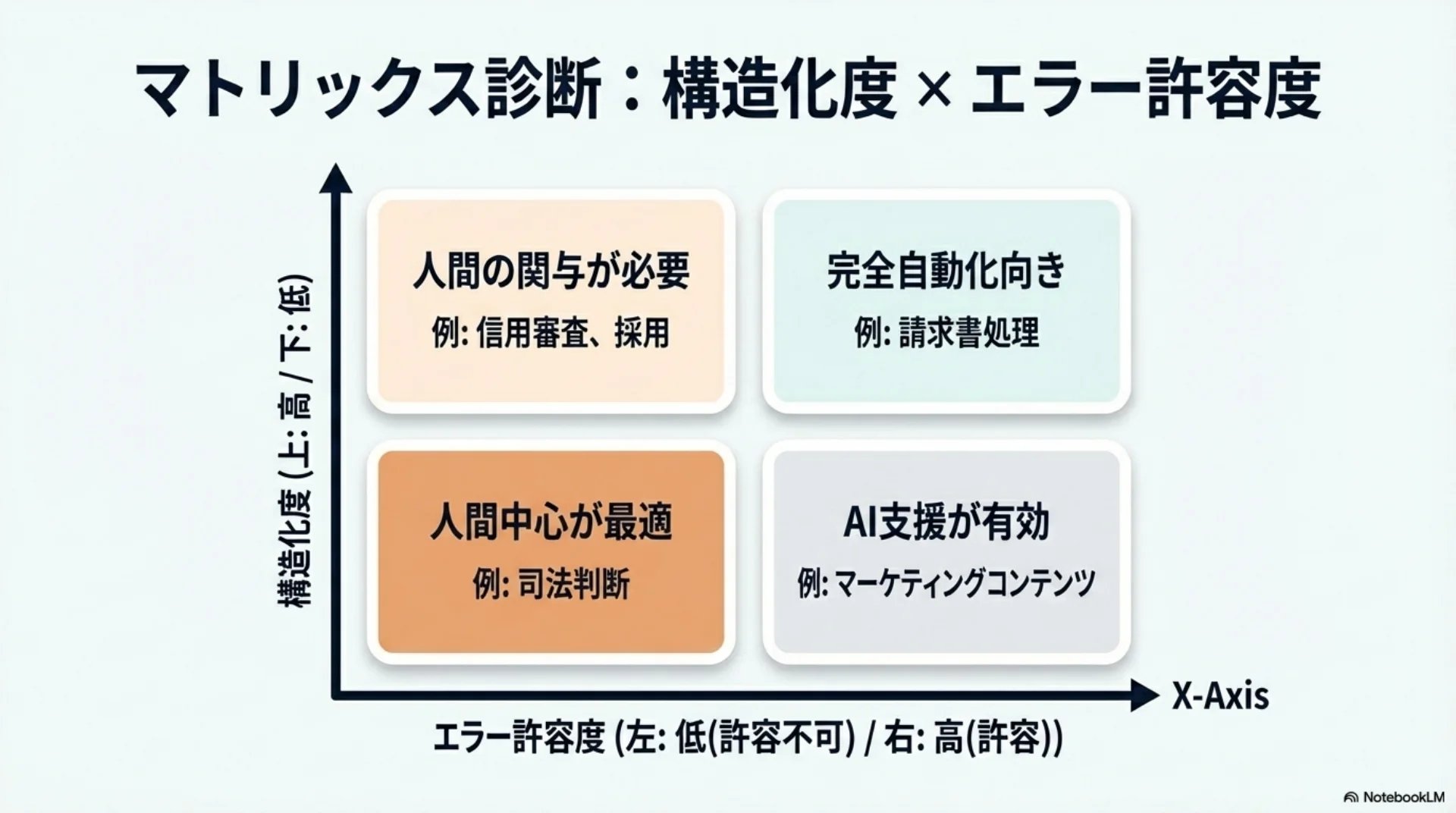
## スライド13: 構造化度×エラー許容度
【図解: 四象限マトリクス】
X軸: 構造化度(低→高)
Y軸: エラー許容度(低→高)
- 右上: レベル1-2 完全自動化向き(請求書処理)
- 左上: レベル2-3(マーケティングコンテンツ)
- 右下: レベル3(信用審査、採用)
- 左下: レベル4-5 人間中心(司法判断)
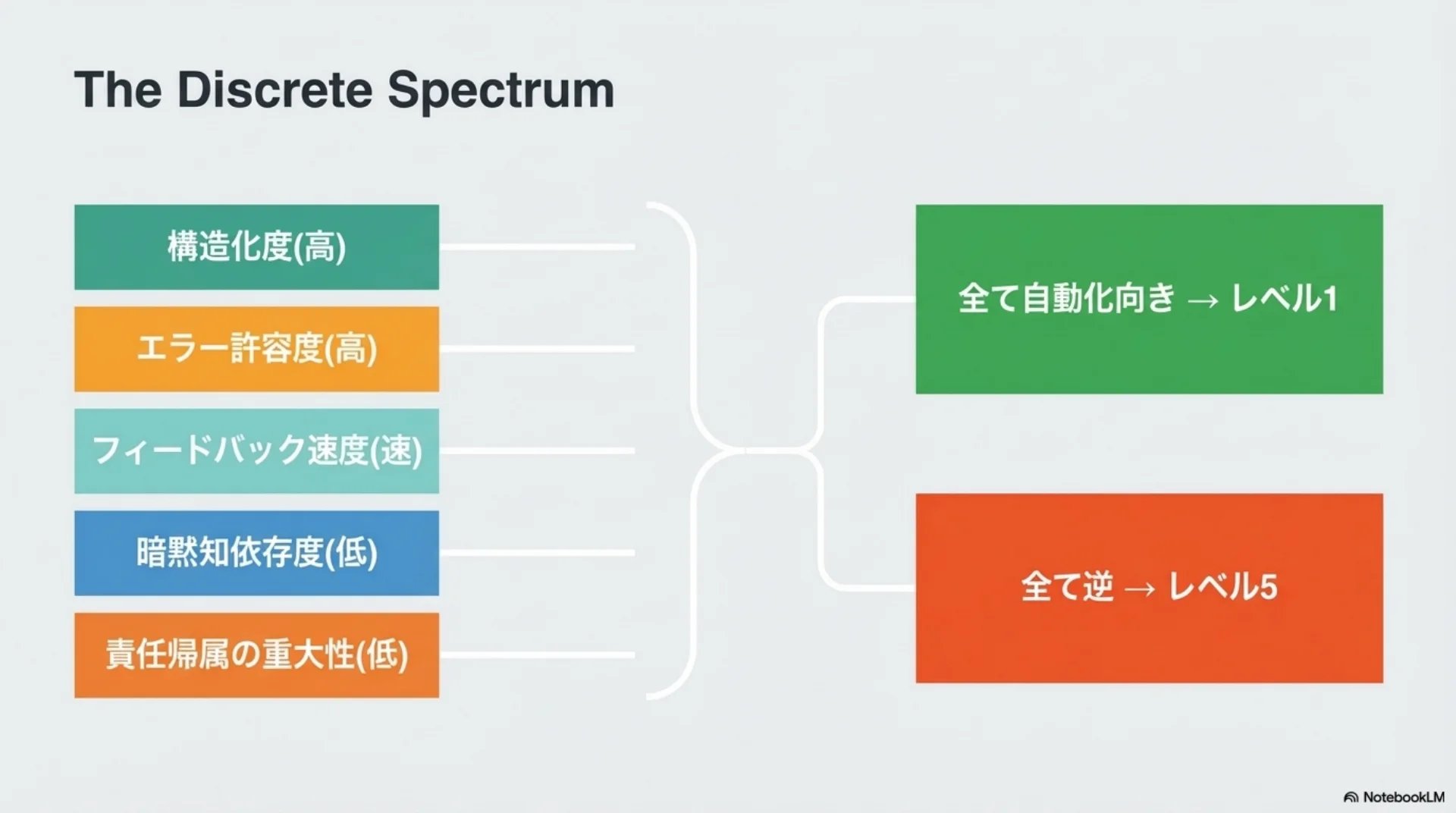
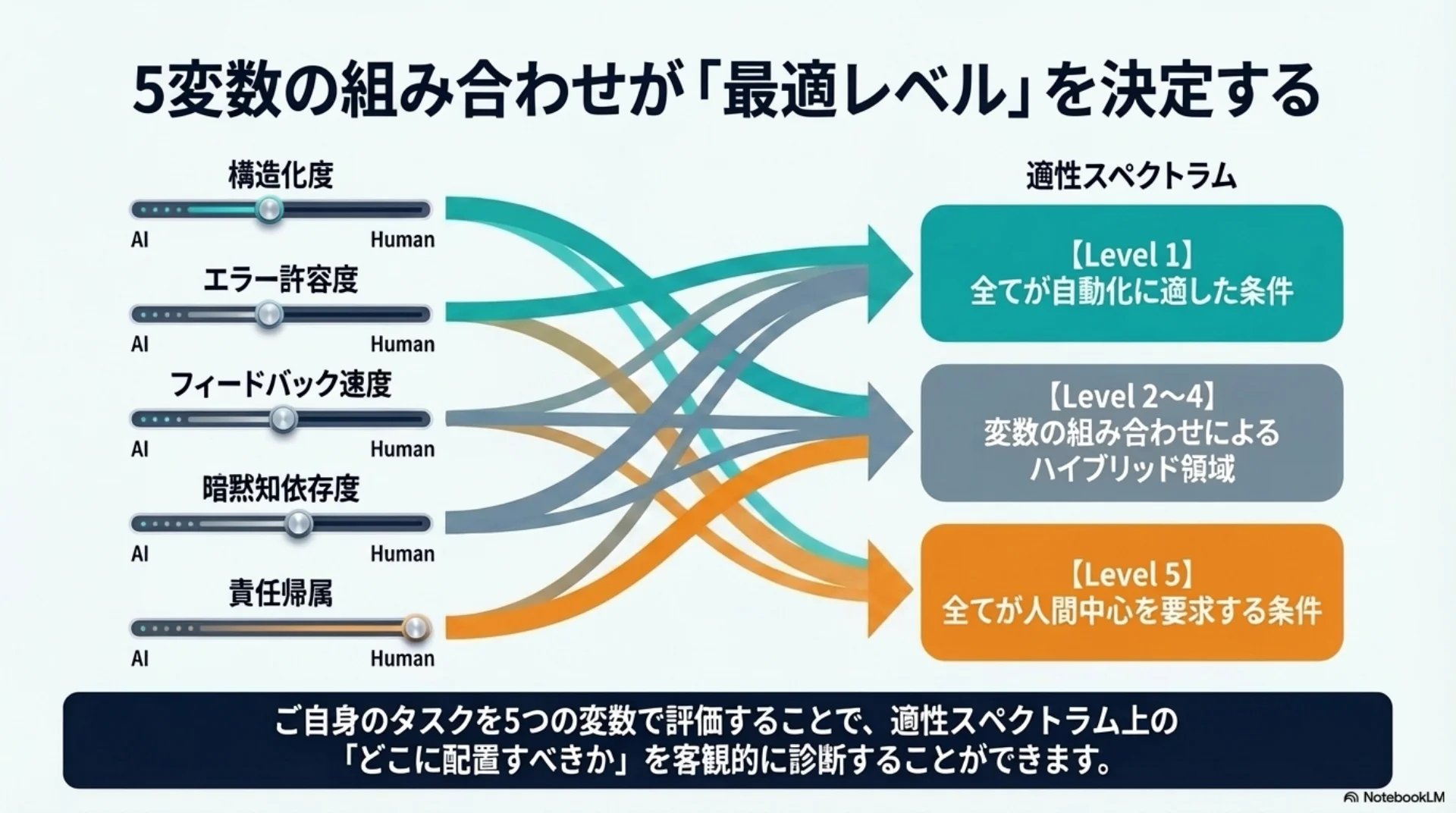
## スライド14: 5変数がレベルを決定する仕組み
【図解: 分解図】
全体: 5変数の組み合わせがレベルを決定
構成要素:
- 構造化度(高→自動化向き)
- エラー許容度(高→自動化向き)
- フィードバック速度(速→自動化向き)
- 暗黙知依存度(低→自動化向き)
- 責任帰属の重大性(低→自動化向き)
全てが自動化向き→レベル1、全てが逆→レベル5パターン1 のカスタムプロンプト(Part B・全文)
以下の構成に厳密に従ってスライドを作成してください。
文章の追加や削除を行わず、ソースドキュメントの構成通りの資料にしてください。
このデッキは全22枚中の前半パート(スライド1〜14)です。
デザインスタイルは他のパートと統一してください。
Slide 1: タイトル(Hero Layout)
Slide 2: 核心メッセージ(Quote Focus, large bold typography)
Slide 3: 適性スペクトラムの5段階(Hierarchical Pyramid, 5 layers, gradient green-to-red base-to-tip)
Slide 4: 自動化向きと人間中心の対比(Split-Screen Comparison, left=green tones, right=orange tones)
Slide 5: セクションタイトル「なぜこう考えたか」(Hero Layout)
Slide 6: 地味な反復処理のROIが高い理由(Hub & Spoke diagram)
Slide 7: AI生産性効果の実態(Iceberg Diagram, clear waterline division, deep blue tones)
Slide 8: 認知バイアスの構造(Hub & Spoke diagram)
Slide 9: ハルシネーションの原理的限界(Quote Focus, large bold typography)
Slide 10: 完全自動化からハイブリッド回帰(Circular Diagram, clockwise arrows, 4 segments)
Slide 11: 精度比較 病理診断(Horizontal Bar Chart, highlight top item)
Slide 12: 5変数モデル(Hub & Spoke diagram with central concept)
Slide 13: 構造化度×エラー許容度(2x2 Matrix Grid with labeled quadrants)
Slide 14: 5変数がレベルを決定する仕組み(Anatomy Breakdown, labeled components)
Maximum 5 bullets per slide. Max 30 words per slide.
対象: テーマに関心のある一般視聴者
トーン: Professional, calm, data-driven, humble, accessible
避けるべき: コードスニペット、学術的な堅苦しさ、カジュアルすぎる表現、過度な専門用語
60% visual / 40% text
Presenter Slides形式(キーポイントのみ表示)
NO stock photos of people
NO gradients
NO decorative borders
Clean stat cards, process flows, comparison layouts, hub-and-spoke diagrams を多用
各スライドは1つの明確なメッセージに集中パターン1 のテキスト版(入力ソース + プロンプト全文)をダウンロード
パターン2: 詳細なスライド構成データのみ + 装飾制限なし
スライド構成データを箇条書き + 説明文で詳細に書き、カスタムプロンプトからは装飾制限を全て外した方式。図解の種類は 14 スライド分すべて明示指定する。ソースはスライド構成データのみで、自然文の台本は渡さない。
装飾に自由度を持たせた分、パターン1 より色使いや強調表現が豊かになる。一方、ソースに書いた情報量がそのままスライドに出てくるため、枝の多い図解ではテキストが詰まりやすい。
パターン2 の方針(要約)
- Part A(ソース)にスライドの全テキストを詳細に記述(箇条書き補足 + 説明文)
- 自然文の台本は渡さない(ソースは Part A のみ)
- Part B で図解種別(
Hierarchical Pyramid,Iceberg Diagram等)を 14 スライド分明示指定 - 装飾制限・ビジュアル比率なし(表現は自由)
パターン2 のソースドキュメント(Part A・全文)
## スライド1: タイトル
タイトル: AI自動化はどこまで任せるべきか?
サブタイトル: 適性スペクトラムの考え方
## スライド2: 核心メッセージ
【キーメッセージ】
「AI化すべきかどうか」ではなく「どのレベルの自動化が最適か」
タスクの性質ごとに最適な自動化レベルが異なる。二択ではなく、5段階のスペクトラムで考える枠組みを「適性スペクトラム」と呼ぶ。
## スライド3: 適性スペクトラムの5段階
【図解: ピラミッド】
5層のピラミッド(下が最も自動化に適する):
頂点(レベル5): AI自動化が不適切 — 司法判断、生殺与奪の決定。社会が人間に留保することを選択する領域
第2層(レベル4): 人間中心+AI支援 — 経営戦略、危機管理。AIはデータ分析を提供、判断は人間
第3層(レベル3): AI支援+HITL — 医療画像診断、法務レビュー。広大なHITL最適ゾーン
第4層(レベル2): 高度自動化+監視 — 一次サポート、品質検査。大部分はAIが処理、異常時に人間へエスカレーション
底辺(レベル1): 完全自動化 — 請求書処理、スパムフィルタ。ルールが明確で大量に反復される
下から緑→黄→オレンジ→赤→濃い赤
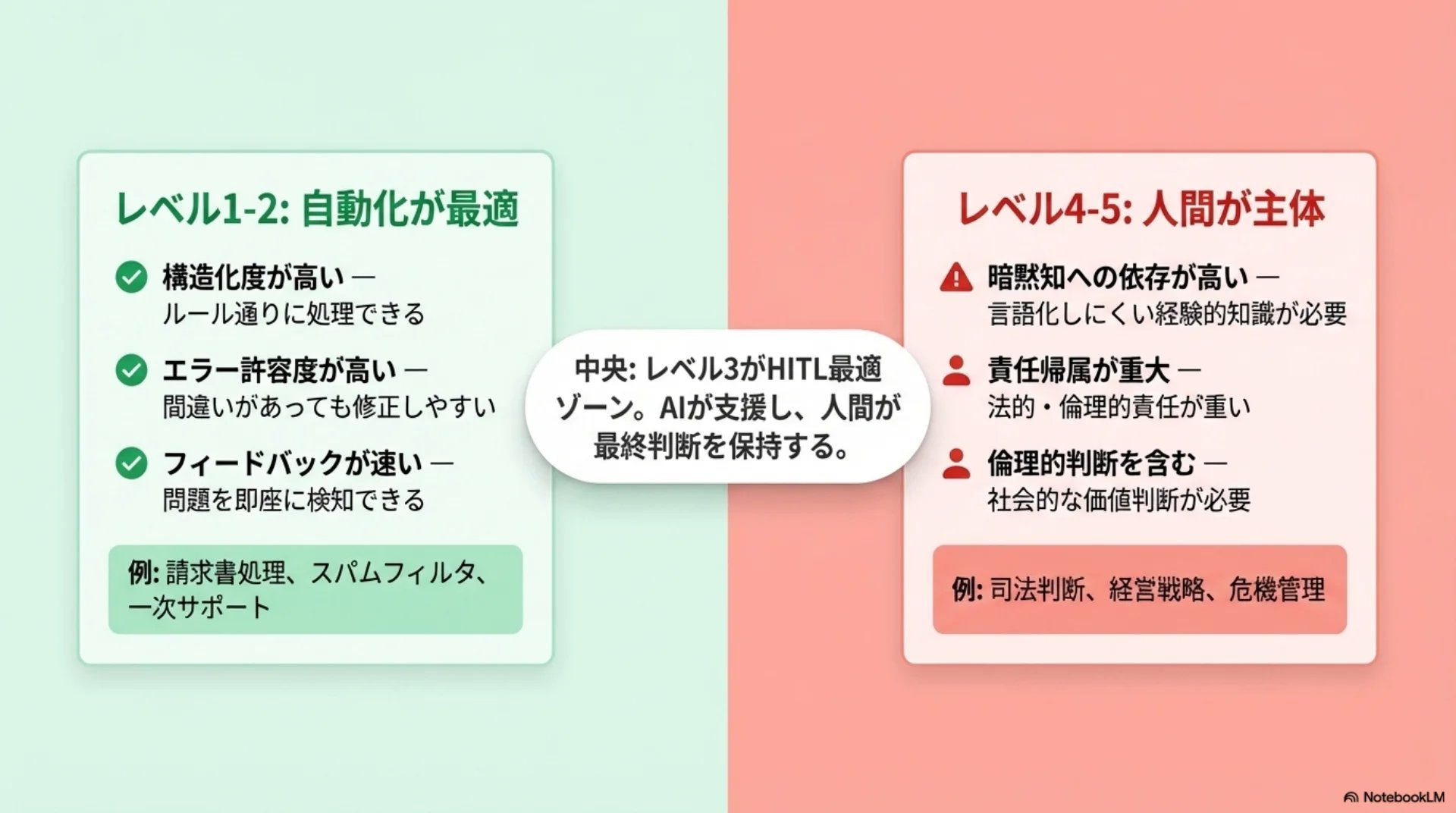
## スライド4: 自動化向きと人間中心の対比
【図解: 対比図】
左「レベル1-2: 自動化が最適」(緑〜黄系):
- 構造化度が高い — ルール通りに処理できる
- エラー許容度が高い — 間違いがあっても修正しやすい
- フィードバックが速い — 問題を即座に検知できる
- 例: 請求書処理、スパムフィルタ、一次サポート
右「レベル4-5: 人間が主体」(オレンジ〜赤系):
- 暗黙知への依存が高い — 言語化しにくい経験的知識が必要
- 責任帰属が重大 — 法的・倫理的責任が重い
- 倫理的判断を含む — 社会的な価値判断が必要
- 例: 司法判断、経営戦略、危機管理
中央: レベル3がHITL最適ゾーン。AIが支援し、人間が最終判断を保持する。
## スライド5: セクションタイトル
タイトル: なぜこう考えたか
サブタイトル: 根拠となる発見
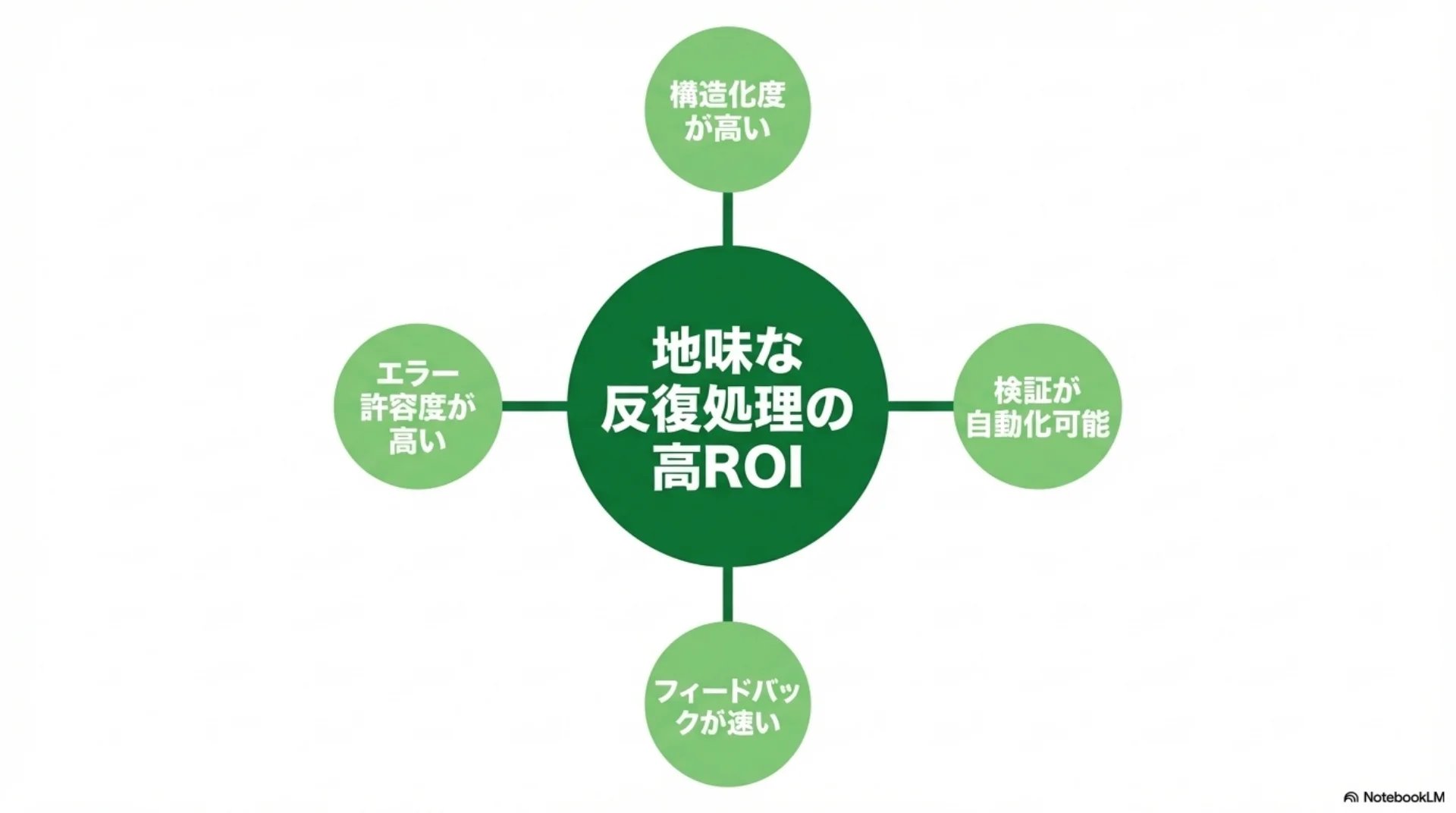
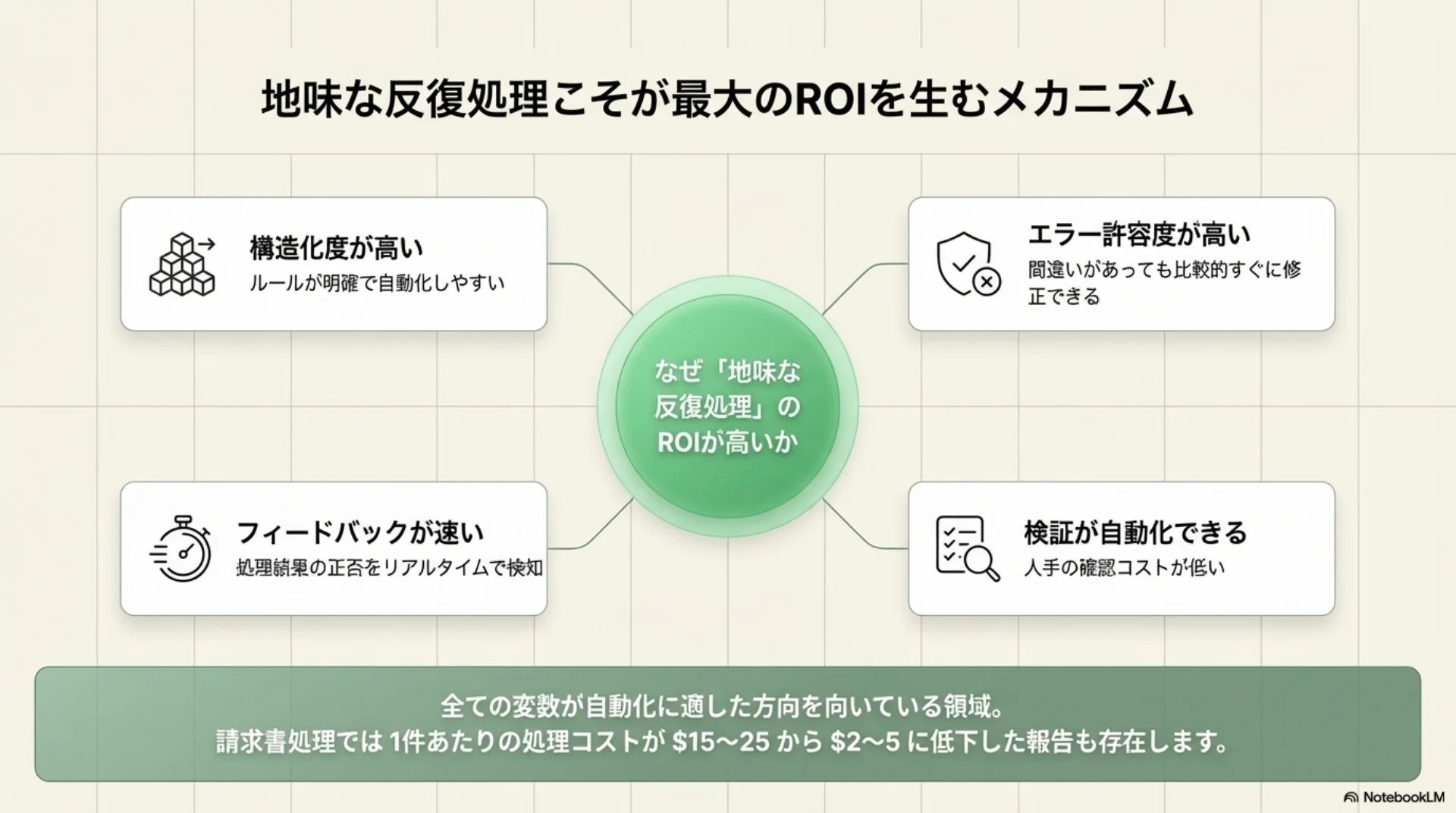
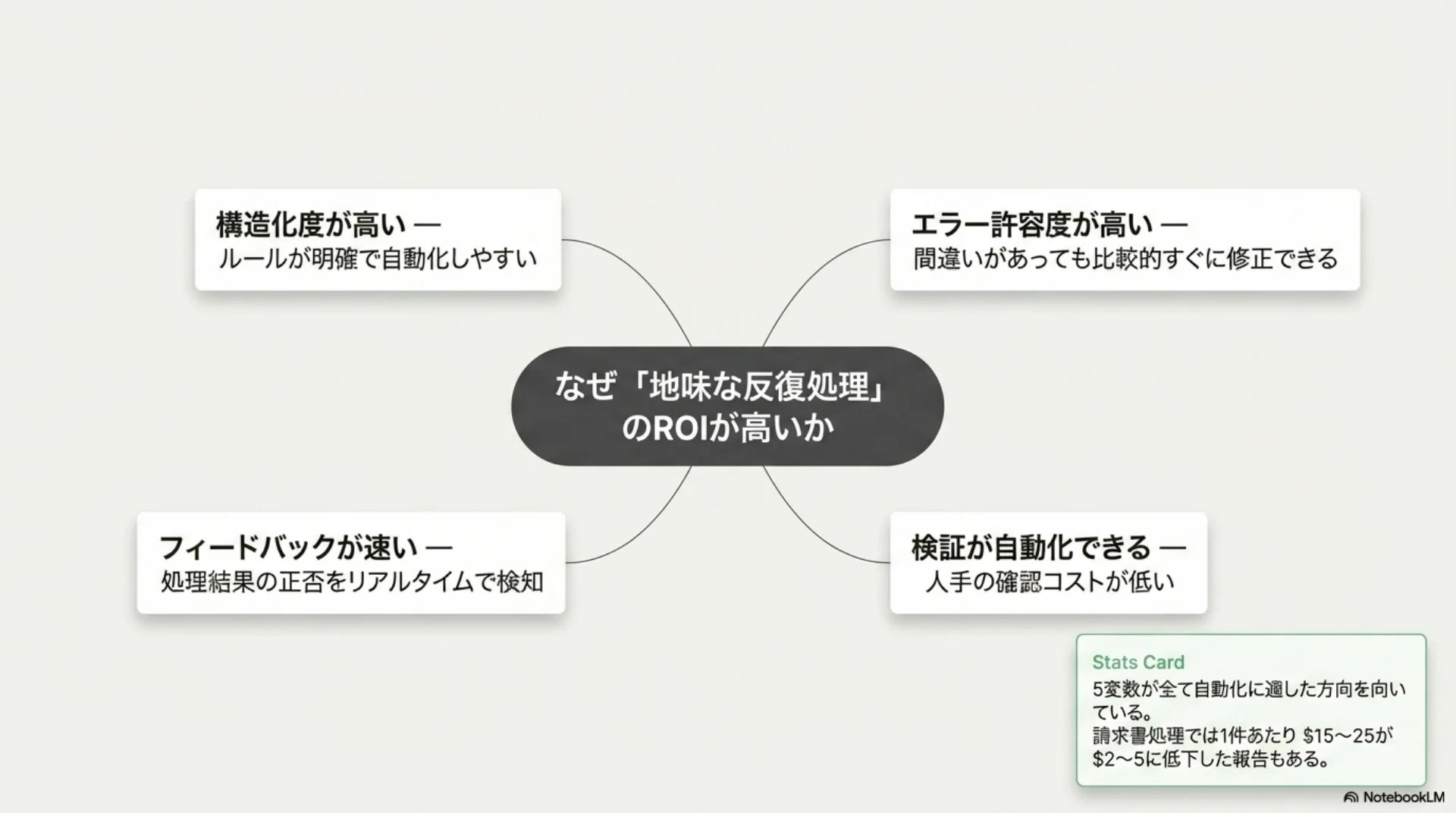
## スライド6: 地味な反復処理のROIが高い理由
【図解: 概念図】
中心: なぜ「地味な反復処理」のROIが高いか
放射状に4つの理由:
- 構造化度が高い — ルールが明確で自動化しやすい
- エラー許容度が高い — 間違いがあっても比較的すぐに修正できる
- フィードバックが速い — 処理結果の正否をリアルタイムで検知
- 検証が自動化できる — 人手の確認コストが低い
5変数が全て自動化に適した方向を向いている。請求書処理では1件あたり$15〜25が$2〜5に低下した報告もある。
## スライド7: AI生産性効果の実態
【図解: 氷山図】
水面上(見えるもの):
- ベンダー調査「55%速くなった」 — GitHub等のスポンサード調査
- 華やかなデモと成功事例 — 注目を集めるAI活用
水面下(見えないもの):
- 独立実験では19%遅くなった — METR研究、経験豊富な開発者が対象
- 知覚と現実に約40ptの乖離 — 遅くなった本人が「速くなった」と信じていた
- 95%のパイロットがP&L効果なし — 損益計算書に測定可能な効果を示せず
- 組織全体では安定性7.2%低下 — 個人の向上と組織の低下が同時に発生
AI効果の測定自体が、想定以上に難しい問題。自己報告ベースのデータには注意が必要。
## スライド8: 認知バイアスの構造
【図解: 概念図】
中心: なぜ効果を過大に感じるか
放射状に3つのメカニズム:
- 自動化バイアス — AIの出力を無批判に受け入れてしまう傾向。カーナビに従い遠回りするのと同じ
- 認知的オフローディング — 負荷が軽減され「楽になった=速くなった」と錯覚する
- 第一印象効果 — 初回の成功体験が過信を固定化する
これらのメカニズムが重なり、知覚と現実に約40ポイントの乖離が生じる。
## スライド9: ハルシネーションの原理的限界
【キーメッセージ】
「ハルシネーションの完全排除は数学的に不可能」
真実性・情報保存・関連知識開示・最適性の4性質を同時に満たせないことが証明されている。2026年現在でも最良モデルのエラー率は6.2%。推論強化モデルでは40%→58%に悪化するケースもある。
## スライド10: 完全自動化からハイブリッド回帰
【図解: 循環図】
時計回りに4段階:
1. AI完全自動化を導入・人員削減
2. スケールアップで困難なケースが増加
3. 品質低下が顕在化 — 顧客満足度22%低下、ドライブスルー精度問題で100店舗撤去
4. 人間とのハイブリッドに回帰 — 解雇した従業員を再雇用
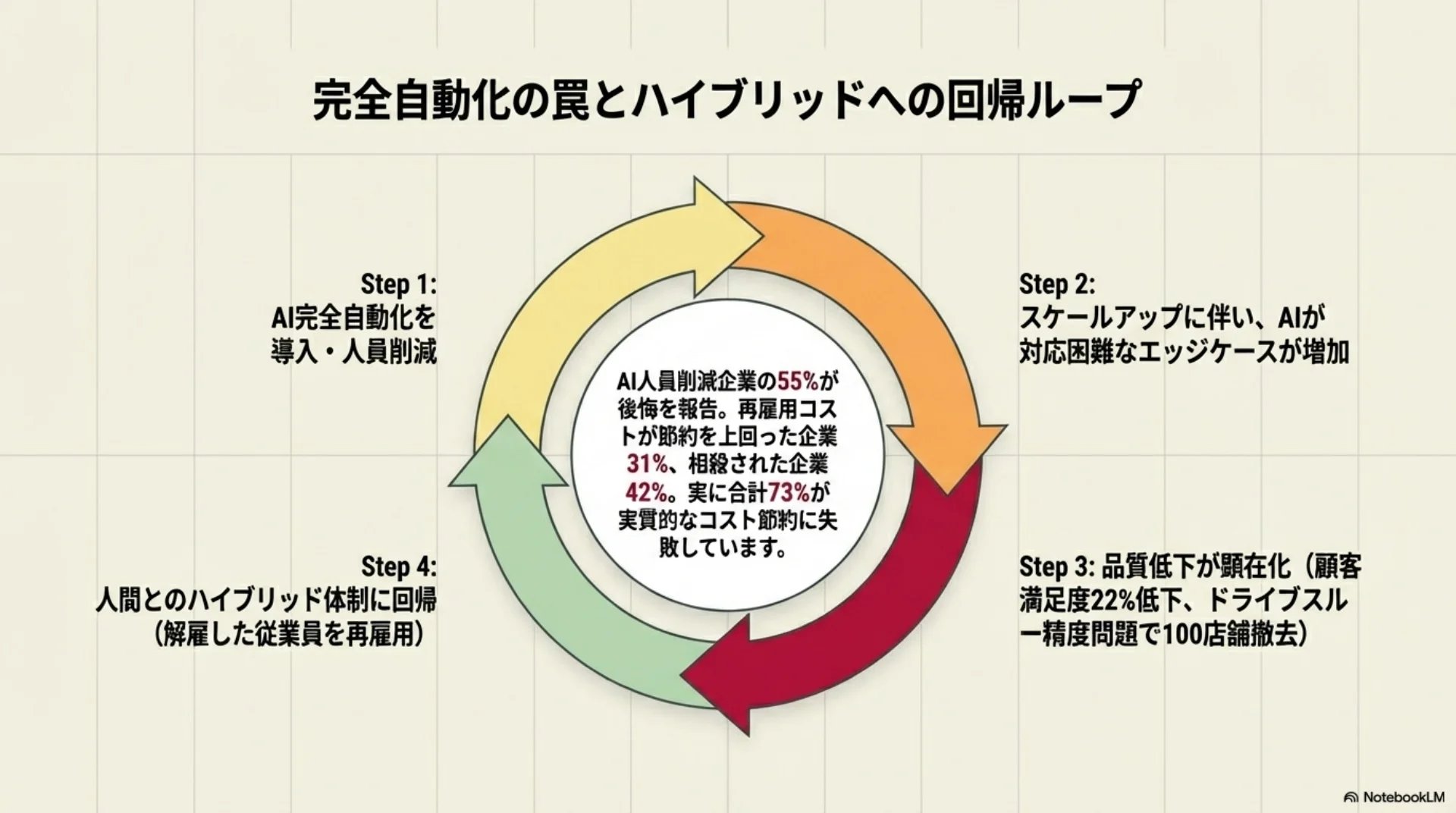
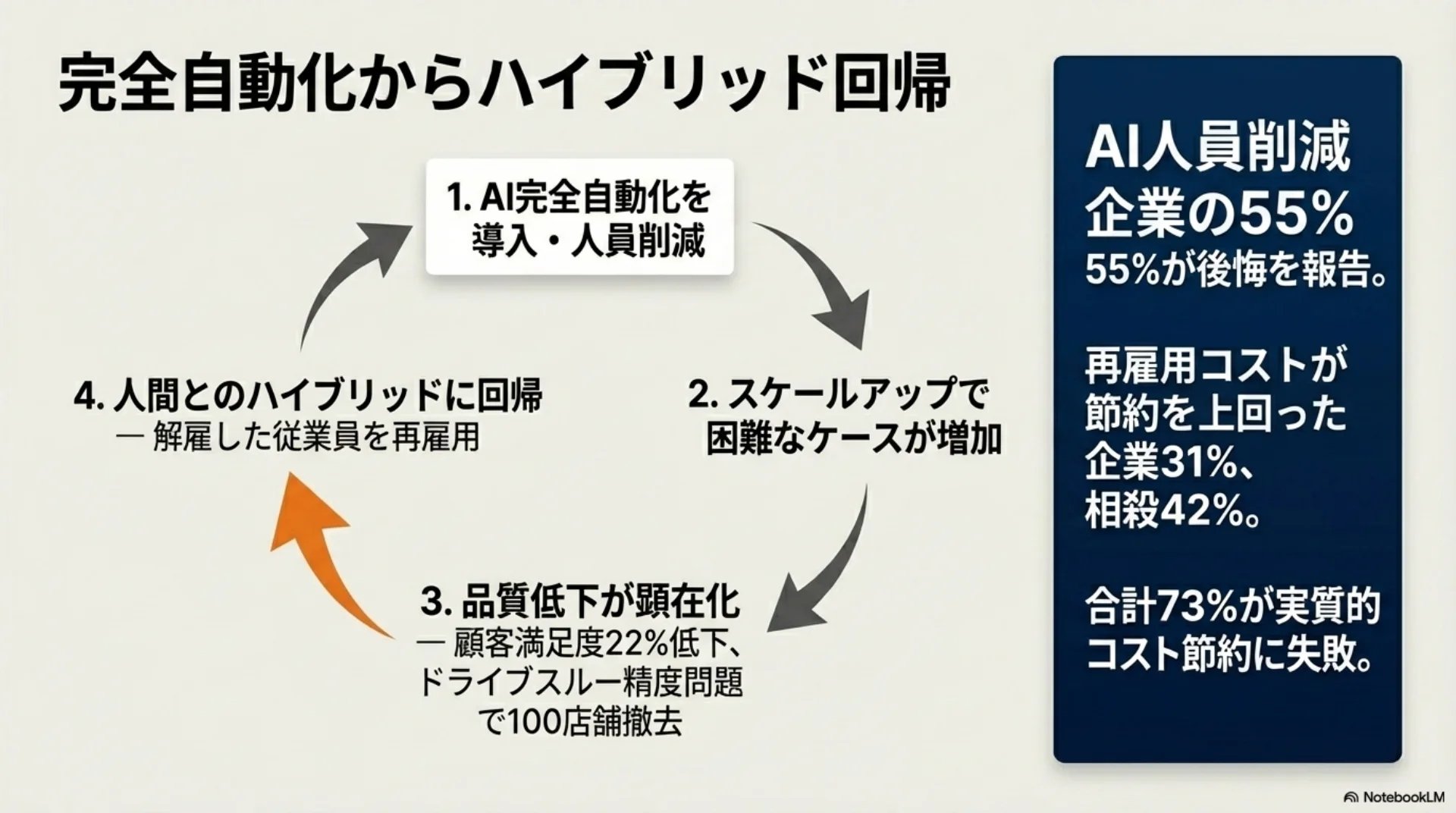
AI人員削減企業の55%が後悔を報告。再雇用コストが節約を上回った企業31%、相殺42%。合計73%が実質的コスト節約に失敗。
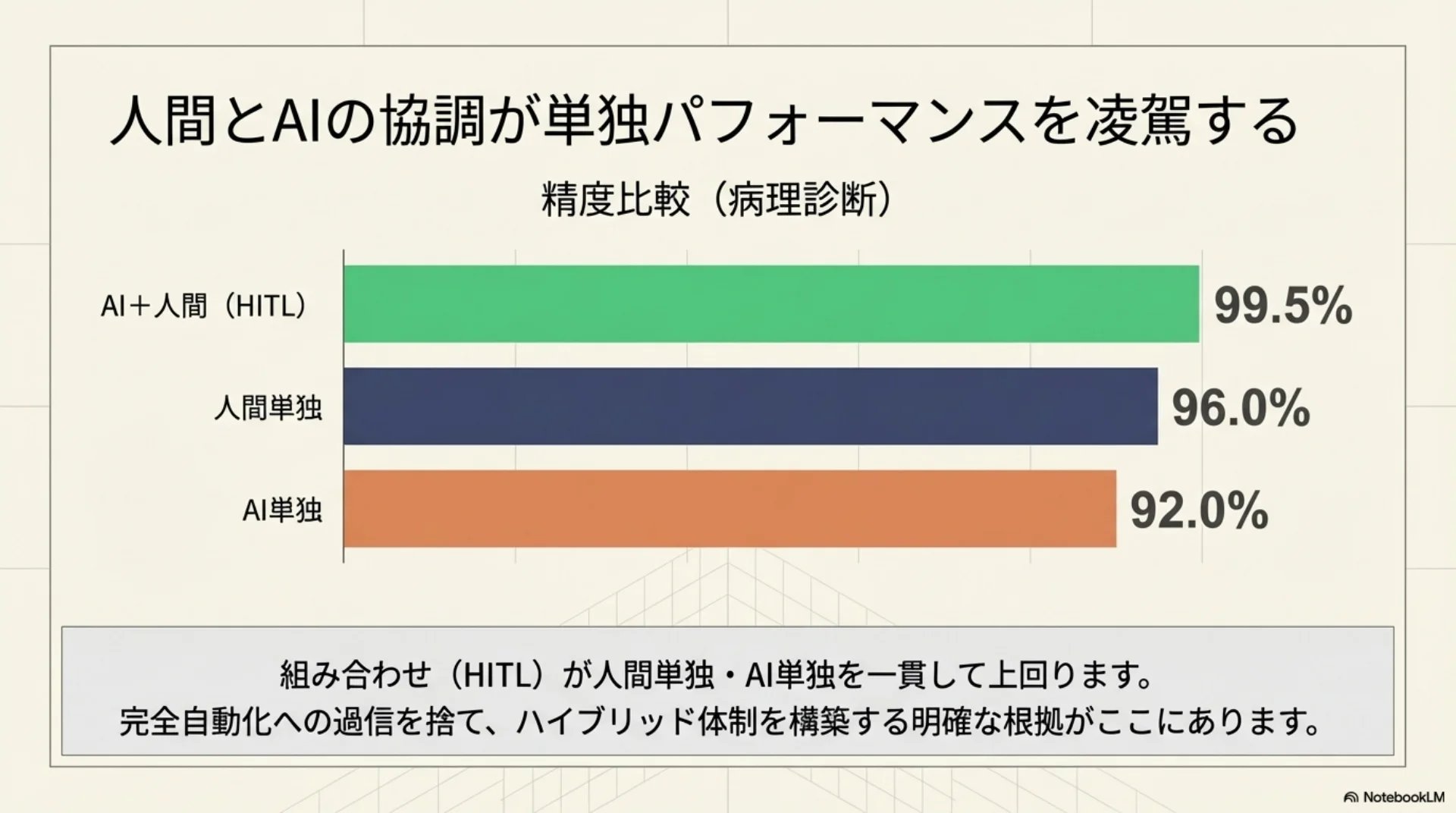
## スライド11: 精度比較(病理診断)
【図解: 横棒グラフ】
- AI+人間(HITL): 99.5%(緑、ハイライト)
- 人間単独: 96%(青)
- AI単独: 92%(オレンジ)
組み合わせが単独を一貫して上回る。完全自動化からハイブリッドに回帰するだけの明確な根拠がある。
## スライド12: 5変数モデル
【図解: 概念図】
中心: 適性スペクトラムの判断基準
5つの放射状要素:
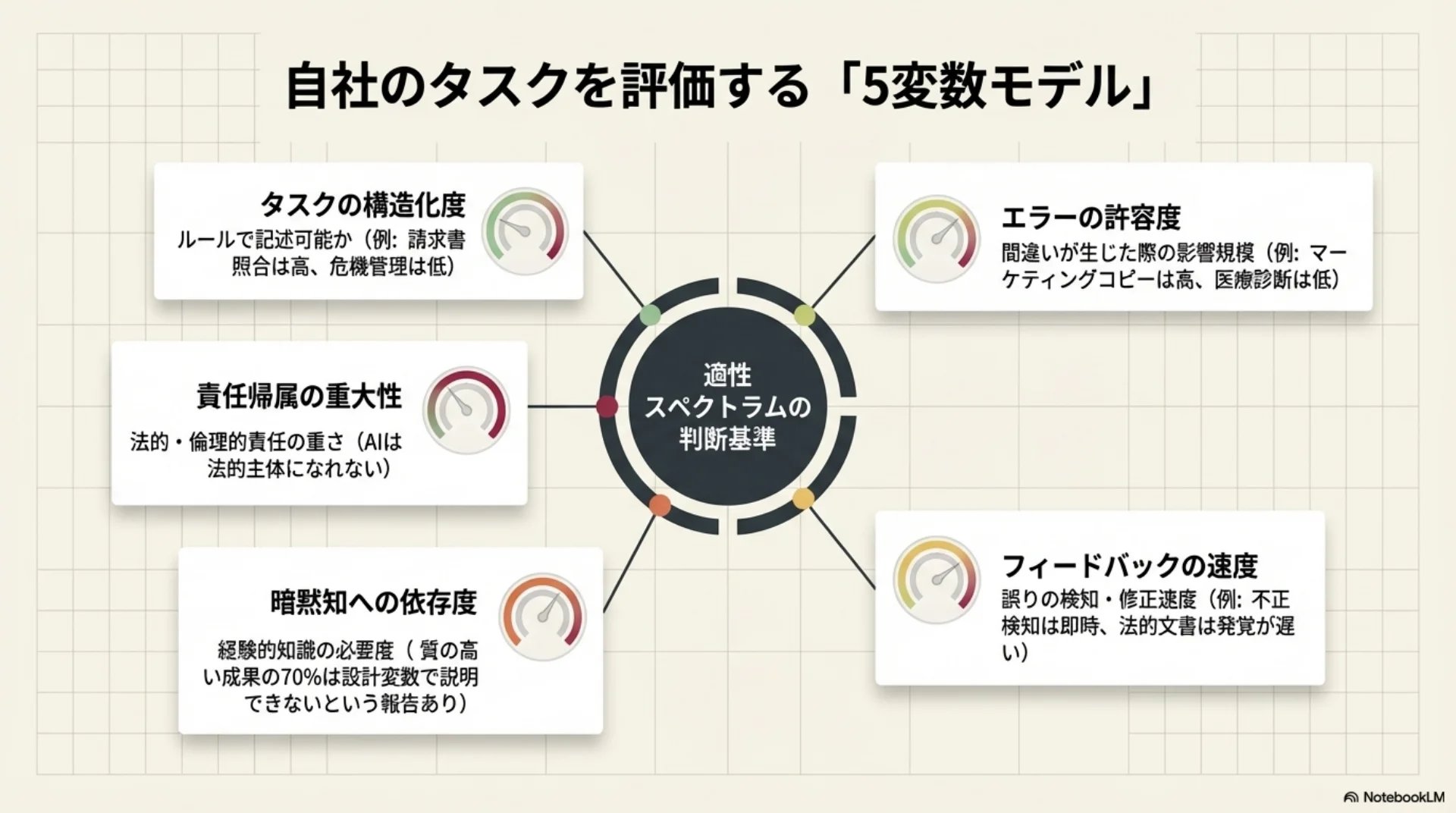
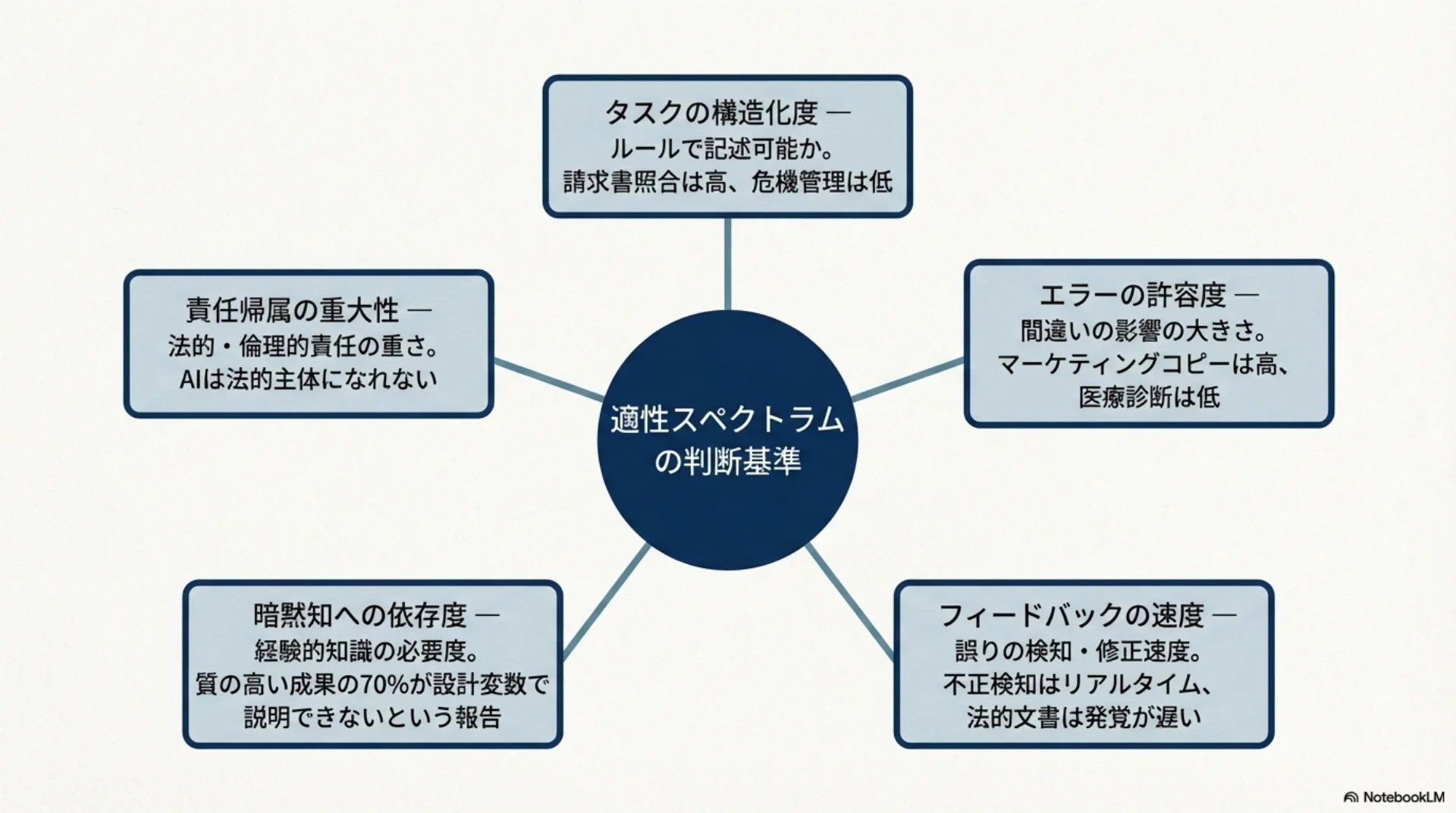
- タスクの構造化度 — ルールで記述可能か。請求書照合は高、危機管理は低
- エラーの許容度 — 間違いの影響の大きさ。マーケティングコピーは高、医療診断は低
- フィードバックの速度 — 誤りの検知・修正速度。不正検知はリアルタイム、法的文書は発覚が遅い
- 暗黙知への依存度 — 経験的知識の必要度。質の高い成果の70%が設計変数で説明できないという報告
- 責任帰属の重大性 — 法的・倫理的責任の重さ。AIは法的主体になれない
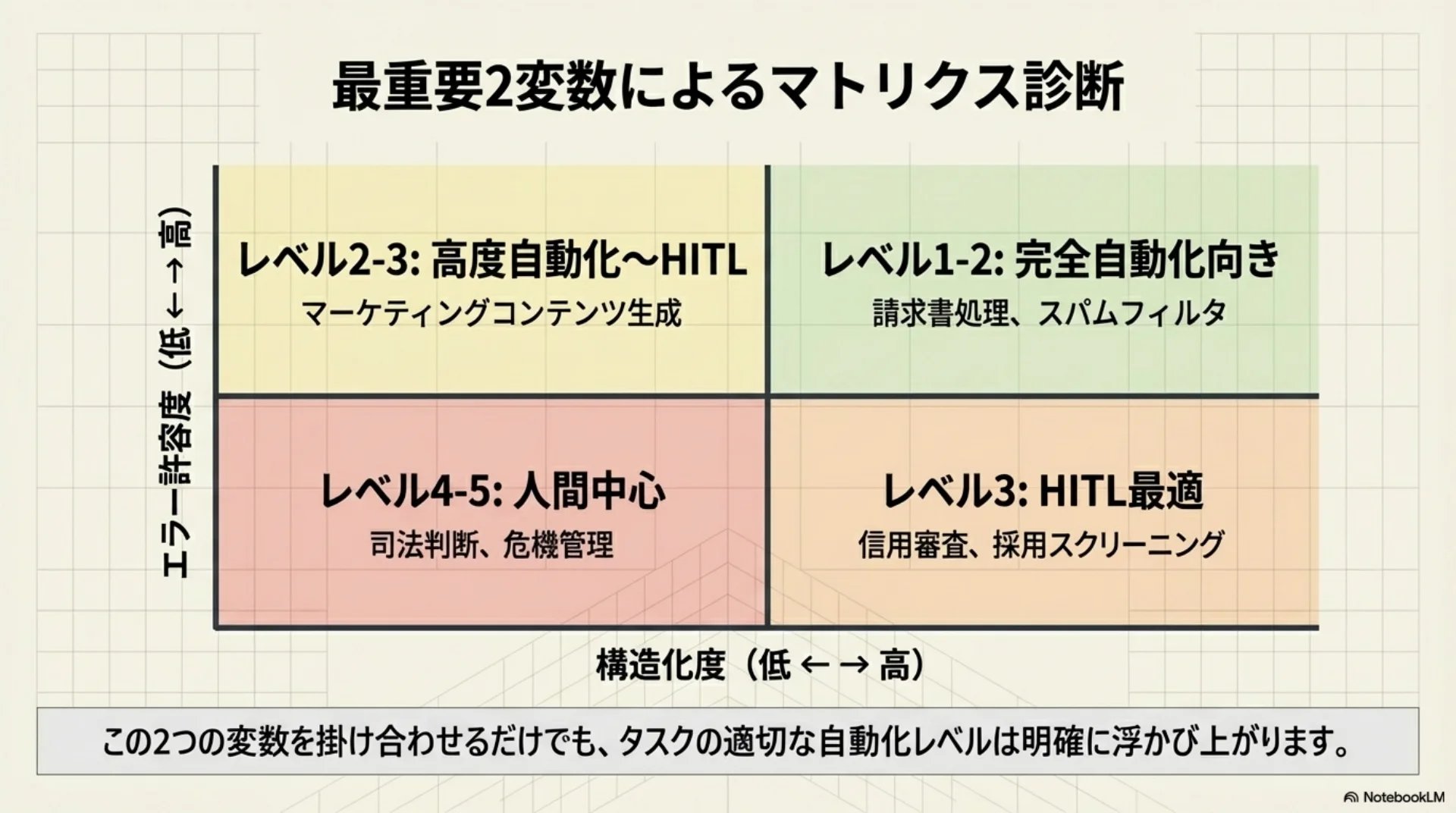
## スライド13: 構造化度×エラー許容度
【図解: 四象限マトリクス】
X軸: 構造化度(低→高)
Y軸: エラー許容度(低→高)
- 右上(高・高): レベル1-2 完全自動化向き — 請求書処理、スパムフィルタ
- 左上(低・高): レベル2-3 — マーケティングコンテンツ生成
- 右下(高・低): レベル3 — 信用審査、採用スクリーニング
- 左下(低・低): レベル4-5 人間中心 — 司法判断、危機管理
この2変数だけでもかなり見えてくる。
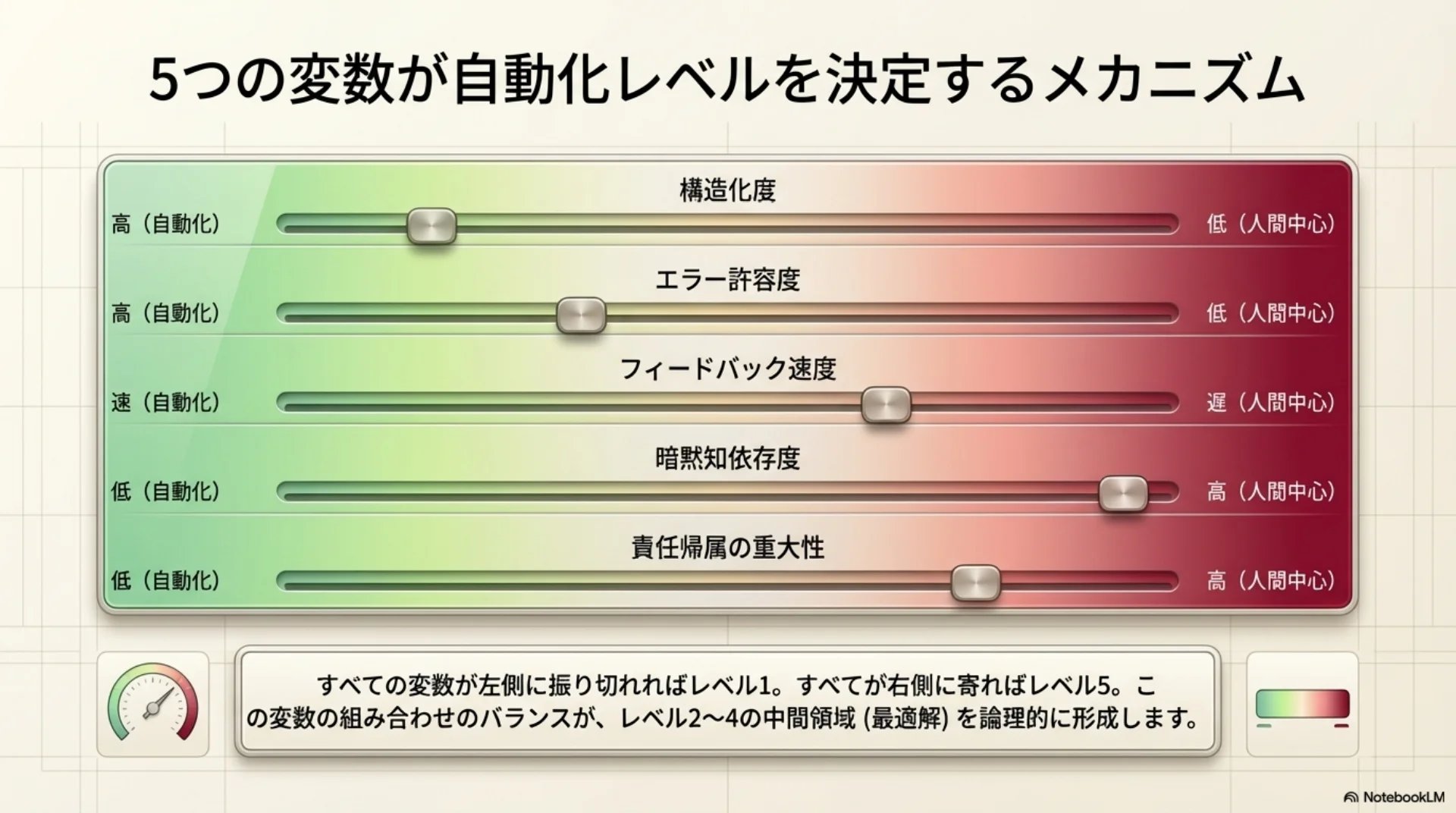
## スライド14: 5変数がレベルを決定する仕組み
【図解: 分解図】
全体: 5変数の組み合わせがレベルを決定
構成要素:
- 構造化度(高→自動化向き / 低→人間中心)
- エラー許容度(高→自動化向き / 低→人間中心)
- フィードバック速度(速→自動化向き / 遅→人間中心)
- 暗黙知依存度(低→自動化向き / 高→人間中心)
- 責任帰属の重大性(低→自動化向き / 高→人間中心)
全てが自動化向き→レベル1、全てが逆→レベル5。中間の組み合わせがレベル2〜4を形成する。パターン2 のカスタムプロンプト(Part B・全文)
Generate EXACTLY 14 slides. Do NOT merge or split any slides. Do NOT add or remove any slides.
以下の構成に厳密に従ってスライドを作成してください。
スライドのテキストはソースドキュメントの内容のみを使用してください。
Slide 1: タイトル(Hero Layout)
Slide 2: 核心メッセージ(Quote Focus, large bold typography)
Slide 3: 適性スペクトラムの5段階(Hierarchical Pyramid, 5 layers, gradient green-to-red base-to-tip)
Slide 4: 自動化向きと人間中心の対比(Split-Screen Comparison, left=green tones, right=orange tones)
Slide 5: セクションタイトル「なぜこう考えたか」(Hero Layout)
Slide 6: 地味な反復処理のROIが高い理由(Hub & Spoke diagram)
Slide 7: AI生産性効果の実態(Iceberg Diagram, clear waterline division, deep blue tones)
Slide 8: 認知バイアスの構造(Hub & Spoke diagram)
Slide 9: ハルシネーションの原理的限界(Quote Focus, large bold typography)
Slide 10: 完全自動化からハイブリッド回帰(Circular Diagram, clockwise arrows, 4 segments)
Slide 11: 精度比較 病理診断(Horizontal Bar Chart, highlight top item)
Slide 12: 5変数モデル(Hub & Spoke diagram with central concept)
Slide 13: 構造化度×エラー許容度(2x2 Matrix Grid with labeled quadrants)
Slide 14: 5変数がレベルを決定する仕組み(Anatomy Breakdown, labeled components)
対象: テーマに関心のある一般視聴者
トーン: Professional, calm, data-driven, humble, accessible
避けるべき: コードスニペット、学術的な堅苦しさ、カジュアルすぎる表現、過度な専門用語
Presenter Slides形式(キーポイントのみ表示)
各スライドは1つの明確なメッセージに集中パターン2 のテキスト版(入力ソース + プロンプト全文)をダウンロード
パターン3: 詳細なスライド構成データ + 自然文の台本 + 装飾制限なし
スライド構成データ(箇条書き)と自然文の台本を 2 つのソースとして NotebookLM に渡す方式。装飾制限なし、図解種別の明示指定あり。カスタムプロンプトでは「スライドのテキストは構成データのみを使う、台本は背景情報として参照する」と明記する。
「構成データで見た目を制御しつつ、台本で文脈を補強する」という折衷案。結論から言うと、今回の検証では台本を参照扱いにすると NotebookLM はほぼ無視し、パターン2 との違いはほとんど出なかった。
パターン3 の方針(要約)
- Part A(ソース)にスライドの全テキストを詳細に記述(箇条書き補足 + 説明文)
- 自然文の台本もソースとして追加登録(背景情報として参照)
- Part B でレイアウト・トーンを制御、ソース名を明記
- 装飾制限・ビジュアル比率なし
パターン3 のソースドキュメント(Part A・全文)
## スライド1: タイトル
タイトル: AI自動化はどこまで任せるべきか?
サブタイトル: 適性スペクトラムの考え方
## スライド2: 核心メッセージ
【キーメッセージ】
「AI化すべきかどうか」ではなく「どのレベルの自動化が最適か」
タスクの性質ごとに最適な自動化レベルが異なる。二択ではなく、5段階のスペクトラムで考える枠組みを「適性スペクトラム」と呼ぶ。
## スライド3: 適性スペクトラムの5段階
【図解: ピラミッド】
5層のピラミッド(下が最も自動化に適する):
頂点(レベル5): AI自動化が不適切 — 司法判断、生殺与奪の決定。社会が人間に留保することを選択する領域
第2層(レベル4): 人間中心+AI支援 — 経営戦略、危機管理。AIはデータ分析を提供、判断は人間
第3層(レベル3): AI支援+HITL — 医療画像診断、法務レビュー。広大なHITL最適ゾーン
第4層(レベル2): 高度自動化+監視 — 一次サポート、品質検査。大部分はAIが処理、異常時に人間へエスカレーション
底辺(レベル1): 完全自動化 — 請求書処理、スパムフィルタ。ルールが明確で大量に反復される
下から緑→黄→オレンジ→赤→濃い赤
## スライド4: 自動化向きと人間中心の対比
【図解: 対比図】
左「レベル1-2: 自動化が最適」(緑〜黄系):
- 構造化度が高い — ルール通りに処理できる
- エラー許容度が高い — 間違いがあっても修正しやすい
- フィードバックが速い — 問題を即座に検知できる
- 例: 請求書処理、スパムフィルタ、一次サポート
右「レベル4-5: 人間が主体」(オレンジ〜赤系):
- 暗黙知への依存が高い — 言語化しにくい経験的知識が必要
- 責任帰属が重大 — 法的・倫理的責任が重い
- 倫理的判断を含む — 社会的な価値判断が必要
- 例: 司法判断、経営戦略、危機管理
中央: レベル3がHITL最適ゾーン。AIが支援し、人間が最終判断を保持する。
## スライド5: セクションタイトル
タイトル: なぜこう考えたか
サブタイトル: 根拠となる発見
## スライド6: 地味な反復処理のROIが高い理由
【図解: 概念図】
中心: なぜ「地味な反復処理」のROIが高いか
放射状に4つの理由:
- 構造化度が高い — ルールが明確で自動化しやすい
- エラー許容度が高い — 間違いがあっても比較的すぐに修正できる
- フィードバックが速い — 処理結果の正否をリアルタイムで検知
- 検証が自動化できる — 人手の確認コストが低い
5変数が全て自動化に適した方向を向いている。請求書処理では1件あたり$15〜25が$2〜5に低下した報告もある。
## スライド7: AI生産性効果の実態
【図解: 氷山図】
水面上(見えるもの):
- ベンダー調査「55%速くなった」 — GitHub等のスポンサード調査
- 華やかなデモと成功事例 — 注目を集めるAI活用
水面下(見えないもの):
- 独立実験では19%遅くなった — METR研究、経験豊富な開発者が対象
- 知覚と現実に約40ptの乖離 — 遅くなった本人が「速くなった」と信じていた
- 95%のパイロットがP&L効果なし — 損益計算書に測定可能な効果を示せず
- 組織全体では安定性7.2%低下 — 個人の向上と組織の低下が同時に発生
AI効果の測定自体が、想定以上に難しい問題。自己報告ベースのデータには注意が必要。
## スライド8: 認知バイアスの構造
【図解: 概念図】
中心: なぜ効果を過大に感じるか
放射状に3つのメカニズム:
- 自動化バイアス — AIの出力を無批判に受け入れてしまう傾向。カーナビに従い遠回りするのと同じ
- 認知的オフローディング — 負荷が軽減され「楽になった=速くなった」と錯覚する
- 第一印象効果 — 初回の成功体験が過信を固定化する
これらのメカニズムが重なり、知覚と現実に約40ポイントの乖離が生じる。
## スライド9: ハルシネーションの原理的限界
【キーメッセージ】
「ハルシネーションの完全排除は数学的に不可能」
真実性・情報保存・関連知識開示・最適性の4性質を同時に満たせないことが証明されている。2026年現在でも最良モデルのエラー率は6.2%。推論強化モデルでは40%→58%に悪化するケースもある。
## スライド10: 完全自動化からハイブリッド回帰
【図解: 循環図】
時計回りに4段階:
1. AI完全自動化を導入・人員削減
2. スケールアップで困難なケースが増加
3. 品質低下が顕在化 — 顧客満足度22%低下、ドライブスルー精度問題で100店舗撤去
4. 人間とのハイブリッドに回帰 — 解雇した従業員を再雇用
AI人員削減企業の55%が後悔を報告。再雇用コストが節約を上回った企業31%、相殺42%。合計73%が実質的コスト節約に失敗。
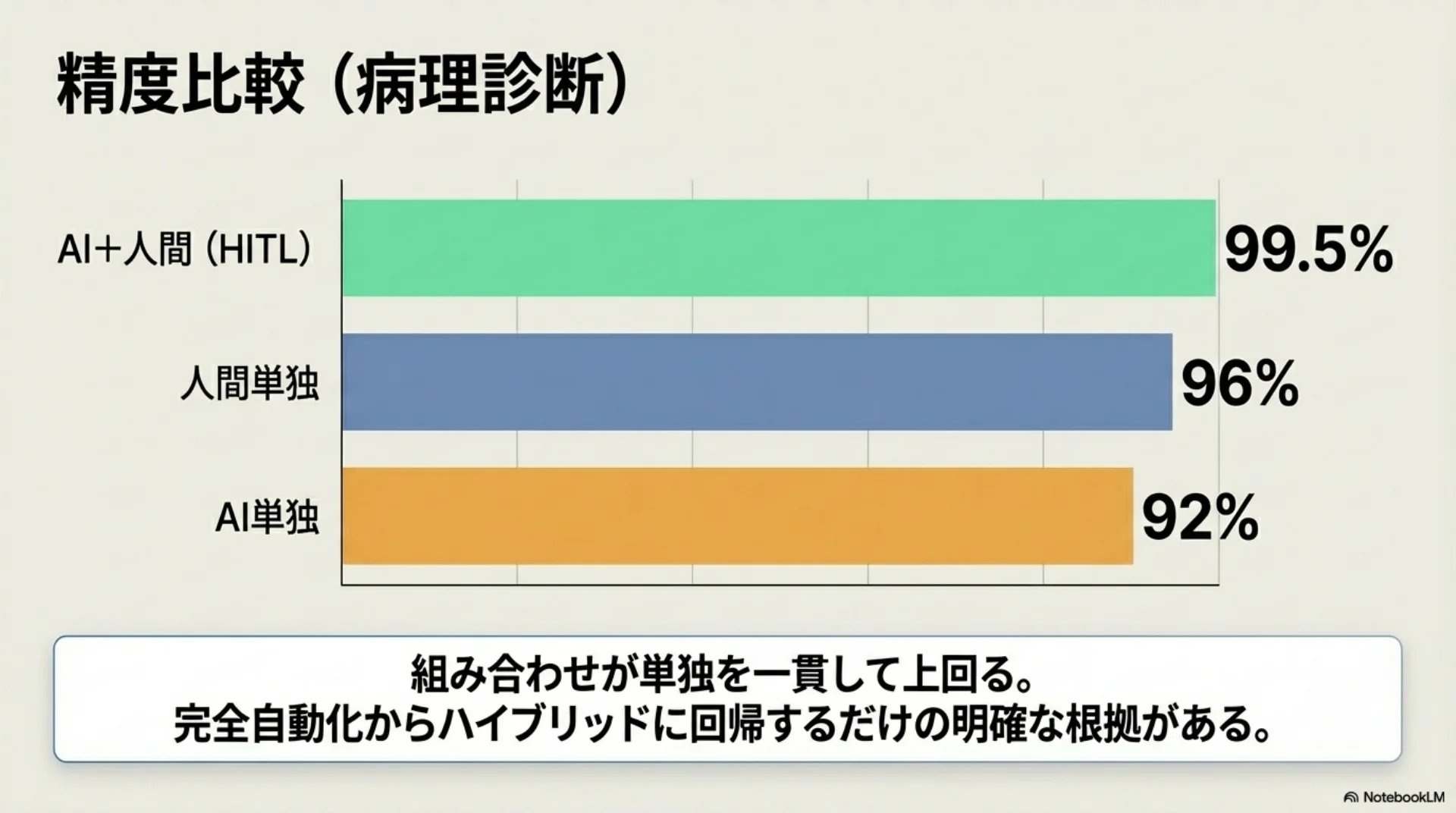
## スライド11: 精度比較(病理診断)
【図解: 横棒グラフ】
- AI+人間(HITL): 99.5%(緑、ハイライト)
- 人間単独: 96%(青)
- AI単独: 92%(オレンジ)
組み合わせが単独を一貫して上回る。完全自動化からハイブリッドに回帰するだけの明確な根拠がある。
## スライド12: 5変数モデル
【図解: 概念図】
中心: 適性スペクトラムの判断基準
5つの放射状要素:
- タスクの構造化度 — ルールで記述可能か。請求書照合は高、危機管理は低
- エラーの許容度 — 間違いの影響の大きさ。マーケティングコピーは高、医療診断は低
- フィードバックの速度 — 誤りの検知・修正速度。不正検知はリアルタイム、法的文書は発覚が遅い
- 暗黙知への依存度 — 経験的知識の必要度。質の高い成果の70%が設計変数で説明できないという報告
- 責任帰属の重大性 — 法的・倫理的責任の重さ。AIは法的主体になれない
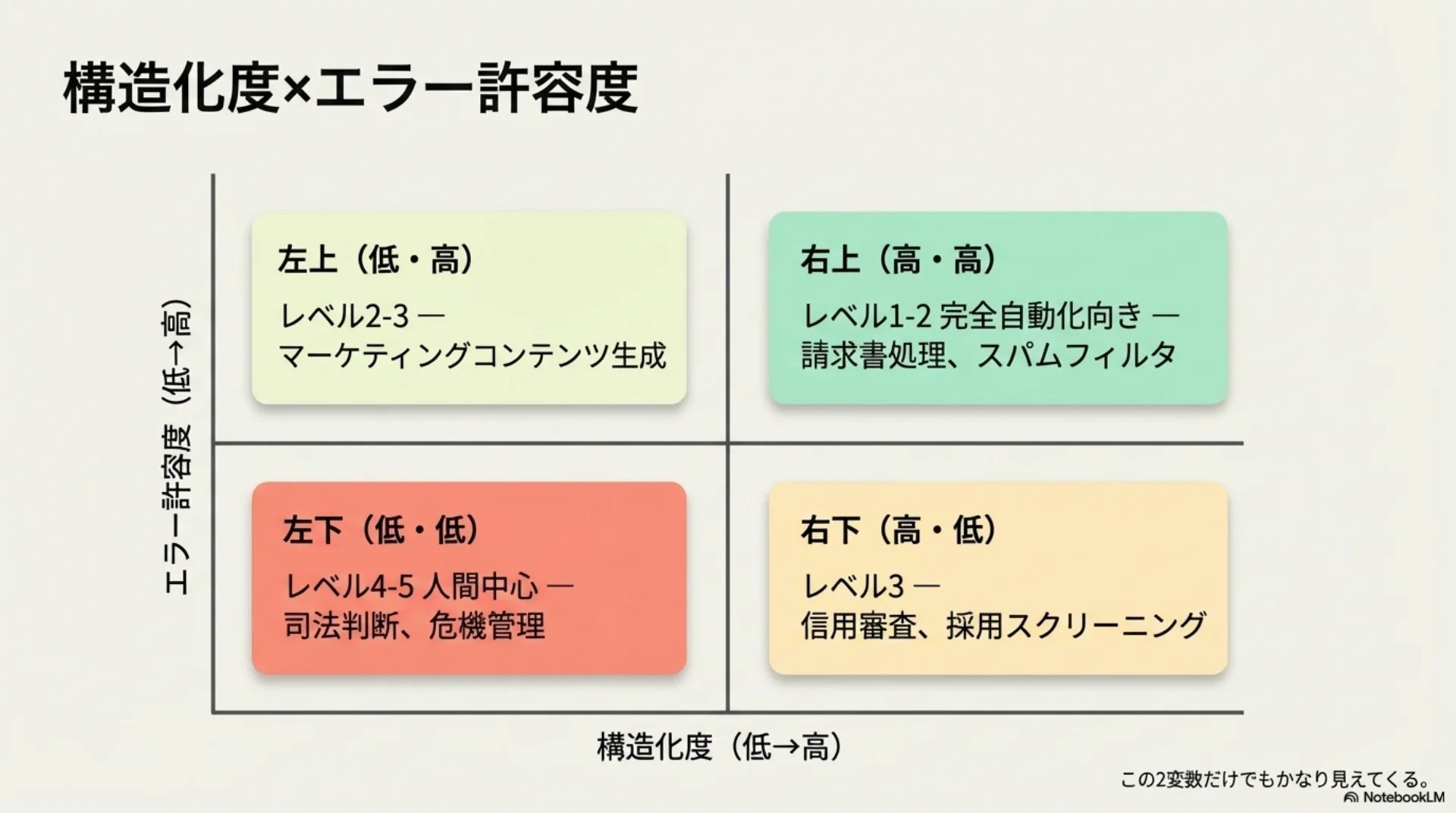
## スライド13: 構造化度×エラー許容度
【図解: 四象限マトリクス】
X軸: 構造化度(低→高)
Y軸: エラー許容度(低→高)
- 右上(高・高): レベル1-2 完全自動化向き — 請求書処理、スパムフィルタ
- 左上(低・高): レベル2-3 — マーケティングコンテンツ生成
- 右下(高・低): レベル3 — 信用審査、採用スクリーニング
- 左下(低・低): レベル4-5 人間中心 — 司法判断、危機管理
この2変数だけでもかなり見えてくる。
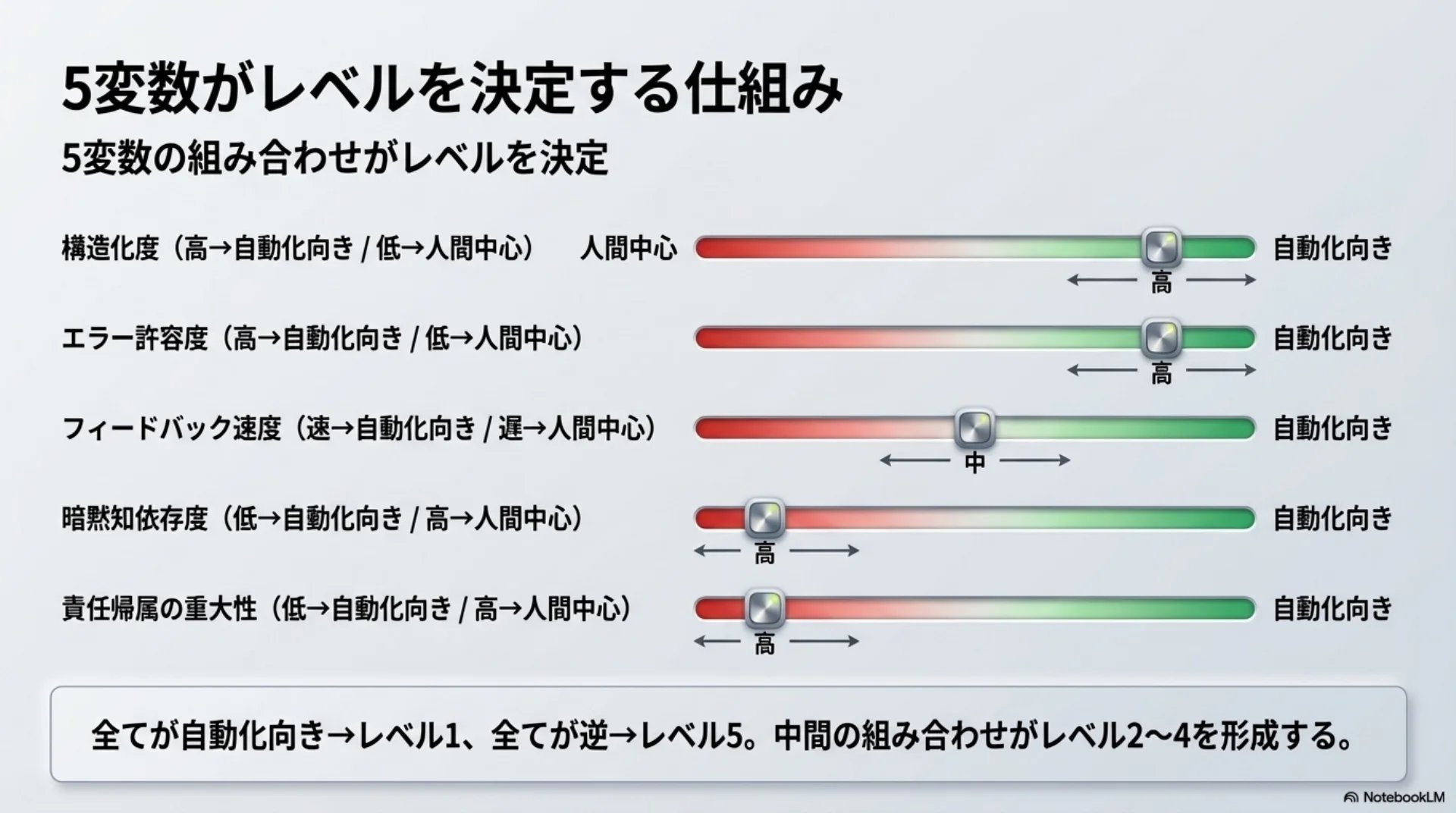
## スライド14: 5変数がレベルを決定する仕組み
【図解: 分解図】
全体: 5変数の組み合わせがレベルを決定
構成要素:
- 構造化度(高→自動化向き / 低→人間中心)
- エラー許容度(高→自動化向き / 低→人間中心)
- フィードバック速度(速→自動化向き / 遅→人間中心)
- 暗黙知依存度(低→自動化向き / 高→人間中心)
- 責任帰属の重大性(低→自動化向き / 高→人間中心)
全てが自動化向き→レベル1、全てが逆→レベル5。中間の組み合わせがレベル2〜4を形成する。※ このパターンでは、上記のスライド構成データに加えて、別途「自然文の台本」を第2のソースとして NotebookLM にアップロードしている。台本全文はパターン4 と同じものなので、次のパターン4 のソースドキュメントを参照のこと。
パターン3 のカスタムプロンプト(Part B・全文)
Generate EXACTLY 14 slides. Do NOT merge or split any slides. Do NOT add or remove any slides.
以下の構成に厳密に従ってスライドを作成してください。
スライドのテキストはソース「スライド構成データ」の内容のみを使用してください。ソース「解説台本」は背景情報・文脈の参照用であり、スライドのテキストには使用しないでください。
Slide 1: タイトル(Hero Layout)
Slide 2: 核心メッセージ(Quote Focus, large bold typography)
Slide 3: 適性スペクトラムの5段階(Hierarchical Pyramid, 5 layers, gradient green-to-red base-to-tip)
Slide 4: 自動化向きと人間中心の対比(Split-Screen Comparison, left=green tones, right=orange tones)
Slide 5: セクションタイトル「なぜこう考えたか」(Hero Layout)
Slide 6: 地味な反復処理のROIが高い理由(Hub & Spoke diagram)
Slide 7: AI生産性効果の実態(Iceberg Diagram, clear waterline division, deep blue tones)
Slide 8: 認知バイアスの構造(Hub & Spoke diagram)
Slide 9: ハルシネーションの原理的限界(Quote Focus, large bold typography)
Slide 10: 完全自動化からハイブリッド回帰(Circular Diagram, clockwise arrows, 4 segments)
Slide 11: 精度比較 病理診断(Horizontal Bar Chart, highlight top item)
Slide 12: 5変数モデル(Hub & Spoke diagram with central concept)
Slide 13: 構造化度×エラー許容度(2x2 Matrix Grid with labeled quadrants)
Slide 14: 5変数がレベルを決定する仕組み(Anatomy Breakdown, labeled components)
対象: テーマに関心のある一般視聴者
トーン: Professional, calm, data-driven, humble, accessible
避けるべき: コードスニペット、学術的な堅苦しさ、カジュアルすぎる表現、過度な専門用語
Presenter Slides形式(キーポイントのみ表示)
Clean stat cards, process flows, comparison layouts, hub-and-spoke diagrams を多用
各スライドは1つの明確なメッセージに集中パターン3 のテキスト版(入力ソース + プロンプト全文)をダウンロード
パターン4: 自然文の台本をそのままソースに + 装飾制限なし
ソースは自然文の台本 1 つだけ。スライド構成用の箇条書きドキュメントは作らない。台本には ## スライドN: のマーカーだけ入れておき、「スライドNに対応するスライドを 1 枚ずつ作ってください」と指示する。カスタムプロンプトは枚数制御とトーン指示のみで、図解種別の明示指定は一切しない。
レイアウトの判断は NotebookLM に任せる。台本に「5段階のピラミッド」「水面上と水面下」「2軸の象限」のような構造的な表現が含まれていれば、NotebookLM がそれを読み取って適切な図解を自動で選ぶ。
(なお、このパターンで使った台本は元動画の全 22 スライド分を含んでいる。本記事の比較対象は他のパターンと揃えて前半 14 枚分だけ。残りは動画本体を公開するときに使う予定。)
パターン4 の方針(要約)
- ソースはスライドマーカー
## スライドN:付きの自然文台本 1 つのみ - カスタムプロンプトは枚数制御とトーン指示のみ(レイアウト種別の指定をしない)
- スライド構成用の別ソースは渡さない
- 装飾制限・ビジュアル比率なし
- 前半パートのプロンプトには「続きがある」旨を明記し、最後のスライドが結論調にならないよう制御
パターン4 のソースドキュメント(自然文の台本・全文、全22スライド分)
## スライド1: タイトル
AI自動化はどこまで任せるべきか? — 適性スペクトラムの考え方
## スライド2: 核心メッセージ
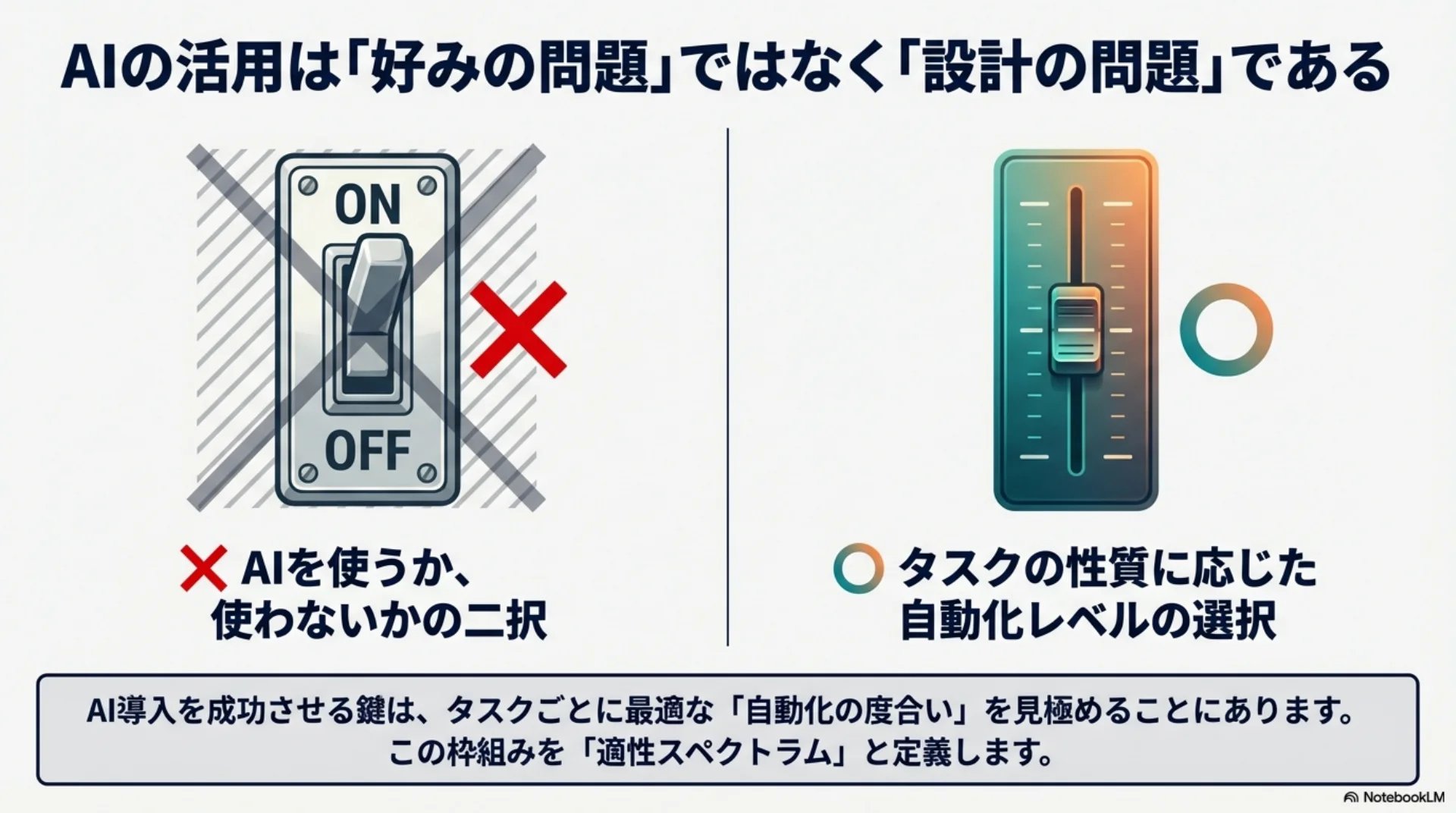
AIにどこまで任せていいのか。これは好みの問題ではなく、設計の問題だと考えています。
さまざまな研究や事例を調べてみて、一つの結論にたどり着きました。「AIを使うか使わないか」という二択ではなく、タスクの性質に応じて最適な自動化レベルを選ぶことが大切ではないか、ということです。この枠組みを「適性スペクトラム」と呼んでみたいと思います。
## スライド3: 適性スペクトラムの5段階
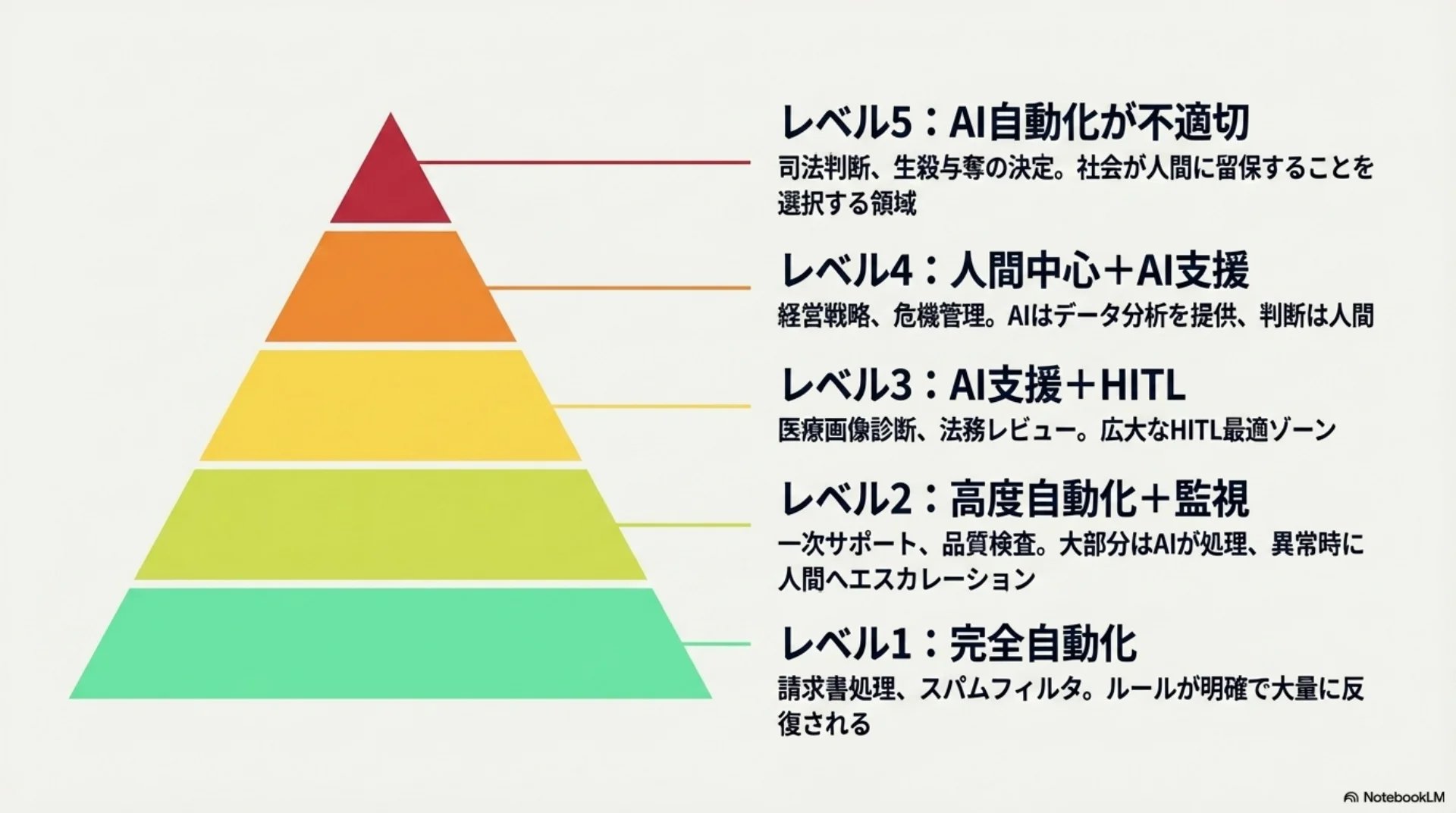
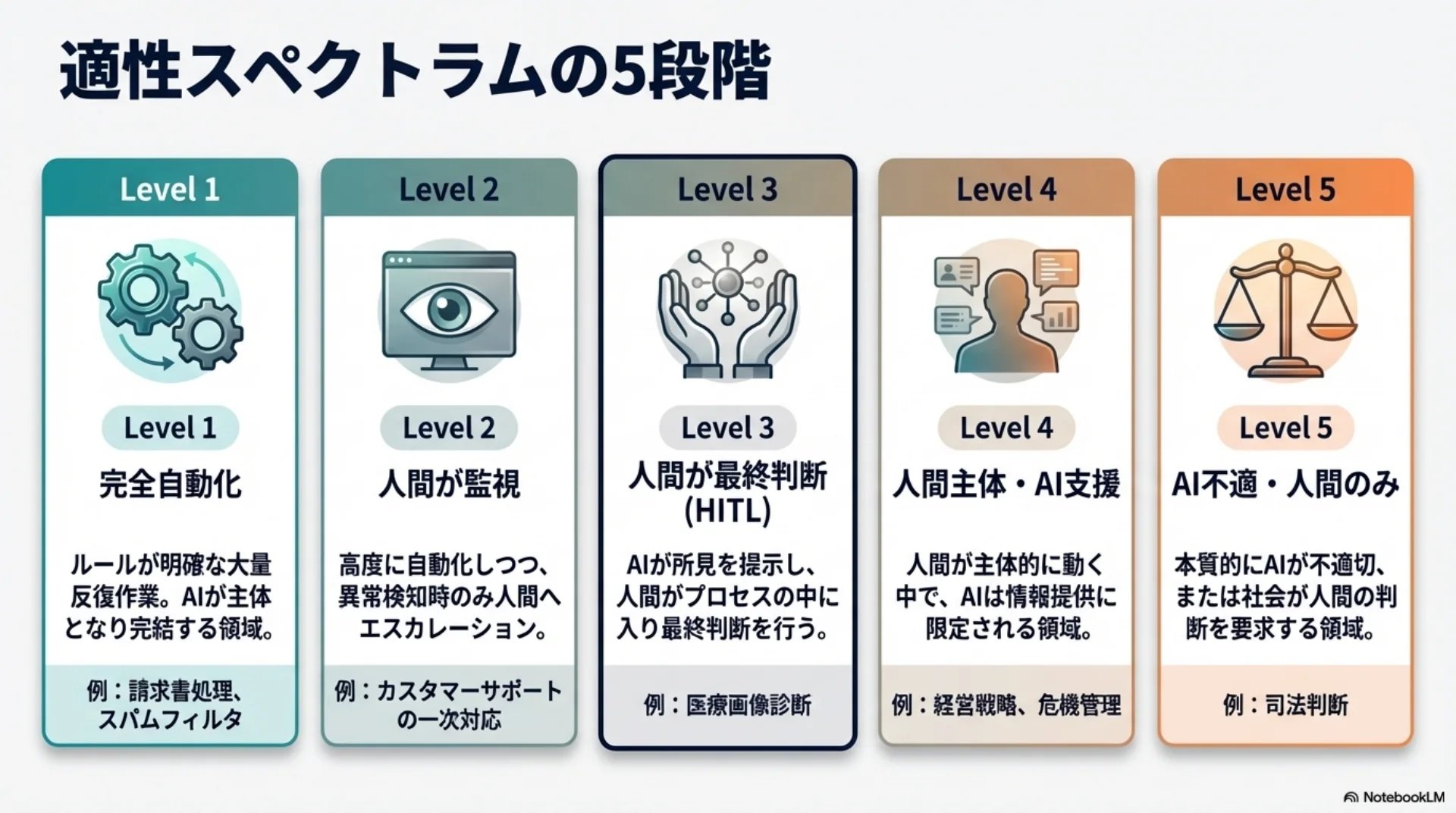
調べた結果、AI自動化の適性は5段階に分かれるようです。
レベル1は、完全自動化が最適な領域です。請求書処理やスパムフィルタリングなど、大量の反復作業がここに入ります。ルールが明確で、量が多く、間違いがあっても比較的すぐに修正できるタスクです。
レベル2は、高度に自動化しつつ人間が監視する形。カスタマーサポートの一次対応や品質検査などですね。大部分はAIが処理しますが、異常があれば人間にエスカレーションされます。
レベル3は、AIが支援しつつ人間が判断を保持する形です。Human-in-the-Loop、つまり人間がプロセスの中に入って最終判断を行う仕組みですね。医療画像診断が分かりやすい例です。
レベル4は、人間が主体でAIは情報提供に限定される領域。経営戦略や危機管理がここに入ります。
そしてレベル5。司法判断のように、AI自動化が本質的に不適切な領域です。社会が特定の判断を人間に留保することを選択する、という側面もあります。
## スライド4: 自動化向きと人間中心の対比
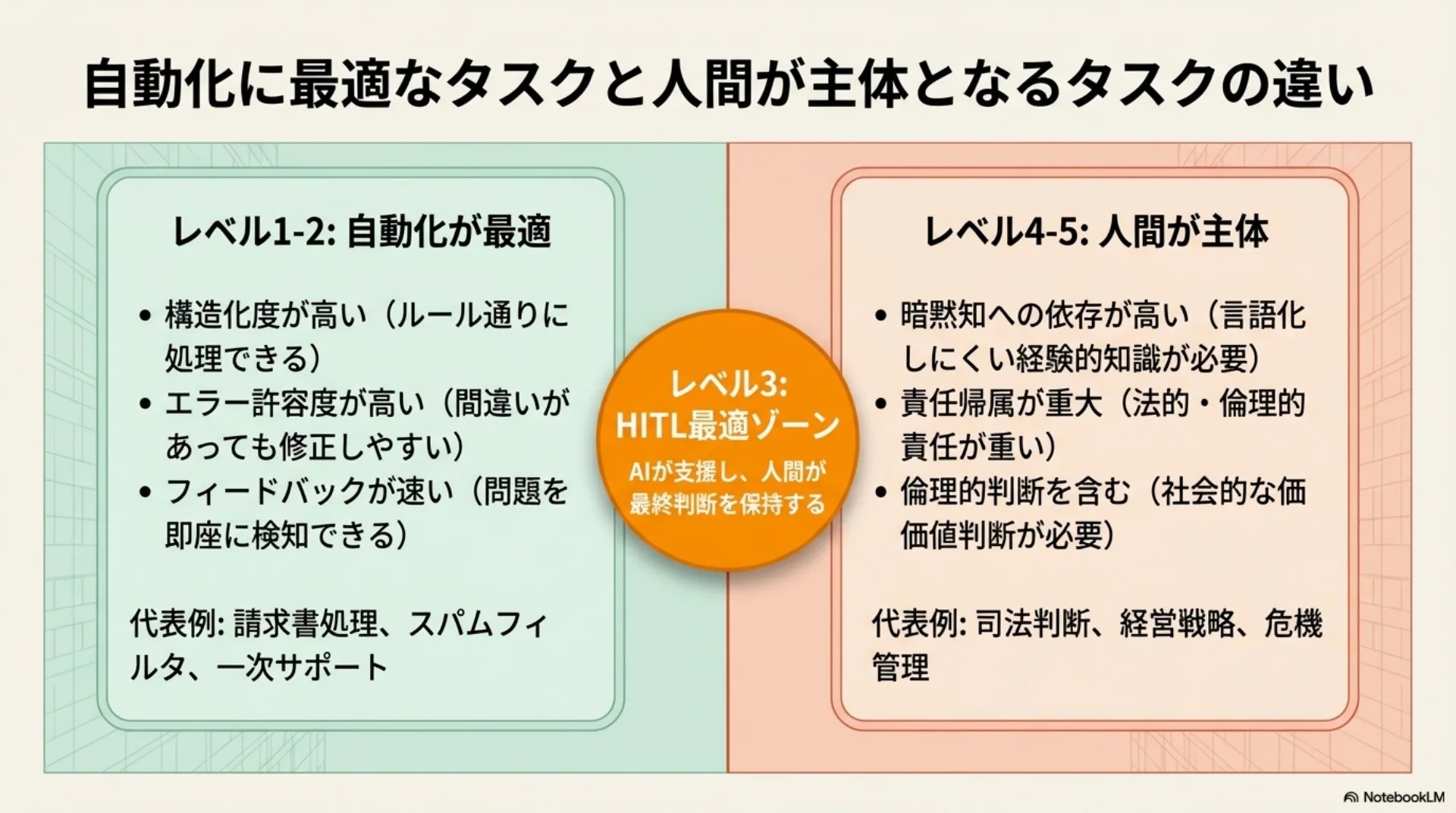
レベル1-2の自動化が最適な領域は、構造化度が高く、エラー許容度が高く、フィードバックが速いという特徴を持ちます。請求書処理やスパムフィルタがその例です。
一方、レベル4-5の人間が主体となる領域は、暗黙知への依存が高く、責任帰属が重大で、倫理的判断を含みます。司法判断や経営戦略がその例です。
レベル3がHITL(Human-in-the-Loop)の最適ゾーンで、AIが所見をハイライトして最終判断は人間が行うような形です。
## スライド5: なぜこう考えたか — 根拠となる発見
ここからは、この5段階の根拠となる発見を順に見ていきます。
## スライド6: 地味な反復処理のROIが高い理由
AI自動化で最も高い投資対効果を示しているのは、注目を集める生成AIやコード生成ではありません。請求書処理やデータ入力のような、地味な反復処理の領域です。
理由は構造にあります。これらのタスクはルールが明確で、大量に反復され、間違いがあっても修正しやすい。さらに、処理が正しいかどうかの検証も自動化できます。つまり、自動化に適した条件が全て揃っている。
請求書処理では1件あたりのコストが15ドルから25ドルだったものが、2ドルから5ドルに下がったという報告もあります。
## スライド7: AI生産性効果の実態
ある独立した実験で、経験豊富な開発者がAIツールを使って実際のタスクに取り組んだところ、むしろ19パーセント遅くなったという結果が出ました。さらに驚くのは、遅くなった本人たちが「20パーセント速くなった」と信じていたことです。知覚と現実に約40ポイントの乖離があります。
一方、ベンダーがスポンサーした調査では「55パーセント速くなった」と報告されています。表面的な成功報告と、独立調査が示す実態には大きなギャップがあります。
別の大規模調査でも、個人レベルでは21パーセント多くのタスクを完了できた一方、組織全体のデリバリー安定性は7.2パーセント低下したと報告されています。生成AIパイロットの95パーセントが損益計算書に対して測定可能な効果を示せていないという調査もあります。
## スライド8: 認知バイアスの構造
なぜ効果を過大に感じるのか。3つの認知バイアスが関わっています。
自動化バイアス: 自動化された結果に過度に頼ってしまう傾向です。カーナビが遠回りのルートを案内しても従ってしまうのと同じです。
認知的オフローディング: 作業の一部をAIに肩代わりしてもらうと、負担が減った感覚がある。実際にはそれほど速くなっていなくても、「楽になった=速くなった」と感じてしまいます。
第一印象効果: 最初の成功体験が過剰な信頼を固定化します。
これらが重なって、知覚と現実に約40ポイントの乖離が生じます。
## スライド9: ハルシネーションの原理的限界
複数の研究チームが異なるアプローチから「ハルシネーションの完全排除は原理的に不可能」と証明しています。真実性、情報の保存、関連知識の開示、最適性。この4つを同時に満たすことが数学的にできないのです。
2026年現在でも最良モデルのエラー率は6.2パーセント。推論を強化したモデルでは逆に40パーセントから58パーセントに悪化するケースもあります。
## スライド10: 完全自動化からハイブリッド回帰
一度は完全自動化に踏み切ったのに、結局人間との協業に戻す、というパターンがさまざまな現場で起きています。
あるフィンテック企業はカスタマーサポートの75パーセントをAIで自動化しましたが、顧客満足度が22パーセント低下し、ハイブリッドモデルに回帰しました。大手ファストフードチェーンでもAIドライブスルー注文の精度問題で100以上の店舗からシステムを撤去しています。
AI導入で人員削減した企業のうち、55パーセントが後悔を報告。再雇用コストが節約額を上回ったケース31パーセント、相殺42パーセント。合わせて73パーセントが実質的コスト節約に失敗しています。
## スライド11: 精度比較(病理診断)
病理診断の分野で、AIと人間を組み合わせたシステムが99.5パーセントの精度を達成しました。AI単独は92パーセント、人間単独は96パーセント。組み合わせが両方を上回っています。
## スライド12: 5変数モデル
タスクの自動化レベルを決める5つの変数があります。
1つ目がタスクの構造化度。明確なルールで記述できるかどうかです。
2つ目がエラーの許容度。間違いが起きたときの深刻さです。
3つ目がフィードバックの速度。誤りをどれだけ早く検知して修正できるかです。
4つ目が暗黙知への依存度。言語化しにくい経験的な知識がどれだけ必要かです。ある研究では、質の高い成果の70パーセントが設計変数では説明できないと報告されています。
5つ目が責任帰属の重大性。AIは法的主体ではないので、責任を負えません。
## スライド13: 構造化度×エラー許容度
構造化度とエラー許容度の2つだけでもかなり見えてきます。
構造化度が高くてエラーが許容できるタスク(請求書処理など)は完全自動化向き。構造化度が低くてもエラー許容度が高いタスク(マーケティングコンテンツ)はAI支援が有効。構造化度が高くてもエラー許容度が低いタスク(信用審査、採用)は人間の関与が必要。両方低いタスク(司法判断)は人間中心が最適です。
## スライド14: 5変数がレベルを決定する仕組み
この5つの変数の組み合わせが、5段階のレベルを決定します。全てが自動化に適した方向ならレベル1。全てが逆ならレベル5。中間の組み合わせがレベル2から4を形成します。自分のタスクがどのレベルに該当するか、この5変数で判断できるのではないかと考えています。
## スライド15: 3つの本質的原則
次に、5変数モデルと並んで重要な3つの原則について考えてみたいと思います。
## スライド16: 増幅器仮説
1つ目は「増幅器仮説」です。AIは万能の生産性ブースターではなく、既存の能力を増幅する装置だという考え方です。
もともとパフォーマンスが高い人はAIで10パーセントから15パーセントさらに向上します。しかし低パフォーマーはむしろ8パーセント業績が下がるという報告があります。コードの品質についても、複製が1.48倍に増えてリファクタリングが減少した。つまりAIが「安易な生成」を増幅してしまった結果です。
ここから導かれるのは、「まず修正し、次に自動化」という順序の大切さです。壊れたプロセスにAIを適用すると、問題が増幅されるだけかもしれません。
## スライド17: 検証のボトルネック
2つ目は「検証のボトルネック」です。AIの出力速度は飛躍的に向上しましたが、その正確性を確認するコストは下がっていません。
ある調査では、AI出力の検証に従業員1人あたり週4.3時間が費やされていると報告されています。時間節約の37パーセントがAI出力のやり直しに消えている。
AI自動化の投資対効果は「生成コストの削減」ではなく「検証コストをいかに抑えるか」で決まるのではないかと考えられます。検証を自動化できるタスクほど恩恵が大きい。
## スライド18: 理想的な実装でも残る限界
セキュリティが万全で最適な設計がなされたとしても、なお残る限界があります。それは3つの層に分かれます。
第1層は数学的・原理的な限界です。ハルシネーションの完全排除が不可能なこと。AIが自分の出力を完全に検証できないこと。Goodhartの法則で代理指標を最適化すると真の目的から逸脱すること。
第2層は人間側の制約です。認知バイアスやスキル喪失の問題があります。AIを4ヶ月使ったグループの83パーセントが要点を想起できなくなり、使用をやめた後も脳活動の低下が続いたという報告があります。
第3層は制度的・法的な制約です。EUでは高リスクAIに人間による実効的な監督が義務付けられ、違反の罰金は全世界年間売上の最大7パーセントです。
この3層は相互に独立しており、1つ解決しても他は残ります。
## スライド19: 技術進歩で改善可能 vs 不可能
技術の進歩で改善可能なものは、精度の向上、処理速度の改善、コストの低下です。
一方、技術進歩では解消不可能なものがあります。ハルシネーション(数学的限界)、認知バイアス(人間側の問題)、法的責任の帰属(制度の問題)、スキル喪失のリスクです。
限界を前提にした設計が必要です。
## スライド20: 実践的な3つの指針
ここまでの内容を3つの指針にまとめます。
第一に、地味な反復処理から始めること。構造化された大量反復タスクが最も高い効果を示しています。導入前に、まず対象のプロセス自体を整理すること。
第二に、Centaur型協業をデフォルトにすること。人間が判断を保持し、AIには特定のサブタスクを任せる。
第三に、限界を前提にフォールバックを組み込むこと。AIが失敗したときの代替手段を最初から設計に含める。
## スライド21: Centaur型協業
Centaur型とは、人間とAIの間に明確な分業を維持するスタイルです。ある研究では、200名以上のコンサルタントの中で、このスタイルを取った14パーセントが最も正確性が高かったと報告されています。
一方、AIに丸投げするSelf-Automator型は、スキルもエンゲージメントも低下していた。人間が判断を保持し、AIには特定のサブタスクを任せる。丸投げではなく分業がポイントです。
## スライド22: まとめ
覚えておいていただきたいメッセージは一つです。AI自動化を考えるとき、「どこまで自動化するか」ではなく、「どこで人間の関与を維持するか」を起点にする。
1. 「地味な反復処理」から始める
2. 「Centaur型協業」をデフォルトに
3. 限界を前提にフォールバックを組み込むパターン4 のカスタムプロンプト(Part B・全文)
# カスタムプロンプト 前半パート(スライド1〜14)
Generate EXACTLY 14 slides. Do NOT merge or split any slides. Do NOT add or remove any slides.
ソース「解説台本」の「スライド1」〜「スライド14」の各セクションに対応するスライドを1枚ずつ作成してください。「スライド15」以降の内容はこのデッキには含めないでください。
対象: テーマに関心のある一般視聴者
トーン: Professional, calm, data-driven, accessible
Presenter Slides形式
各スライドは1つの明確なメッセージに集中
# カスタムプロンプト 後半パート(スライド15〜22)
Generate EXACTLY 8 slides. Do NOT merge or split any slides. Do NOT add or remove any slides.
ソース「解説台本」の「スライド15」〜「スライド22」の各セクションに対応するスライドを1枚ずつ作成してください。「スライド1」〜「スライド14」の内容はこのデッキには含めないでください。
このデッキは全22枚中の後半(スライド15〜22)です。前半(スライド1〜14)は別途作成済みです。デザインスタイルは前半と統一してください。
対象: テーマに関心のある一般視聴者
トーン: Professional, calm, data-driven, accessible
Presenter Slides形式
各スライドは1つの明確なメッセージに集中パターン4 のテキスト版(入力ソース + プロンプト全文)をダウンロード
スライド比較
ここからは、14スライド × 4パターン の生成結果を並べて見ていく。
各スライドブロックはタブで切り替えられる。画像をクリックすると拡大表示され、拡大表示中は ←→ キーで他パターンに切り替え、↑↓ キーで前後のスライドに移動 できる(モバイルではスワイプ)。
スライド1: タイトル




スライド2: 核心メッセージ



スライド3: 適性スペクトラムの5段階


スライド4: 自動化向きと人間中心の対比


スライド5: セクションタイトル「なぜこう考えたか」




スライド6: 地味な反復処理のROIが高い理由

スライド7: AI生産性効果の実態(氷山図)



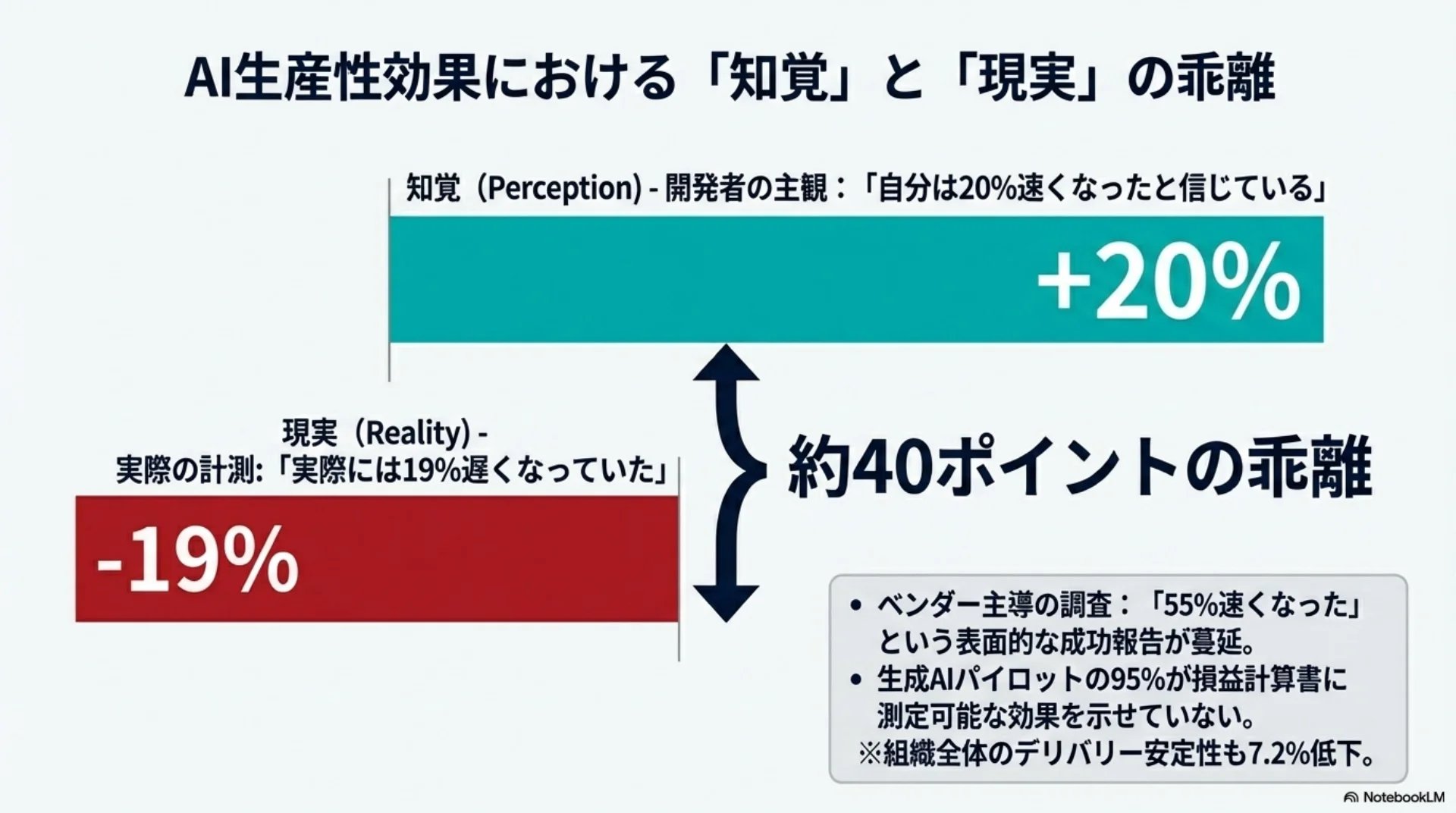
スライド8: 認知バイアスの構造
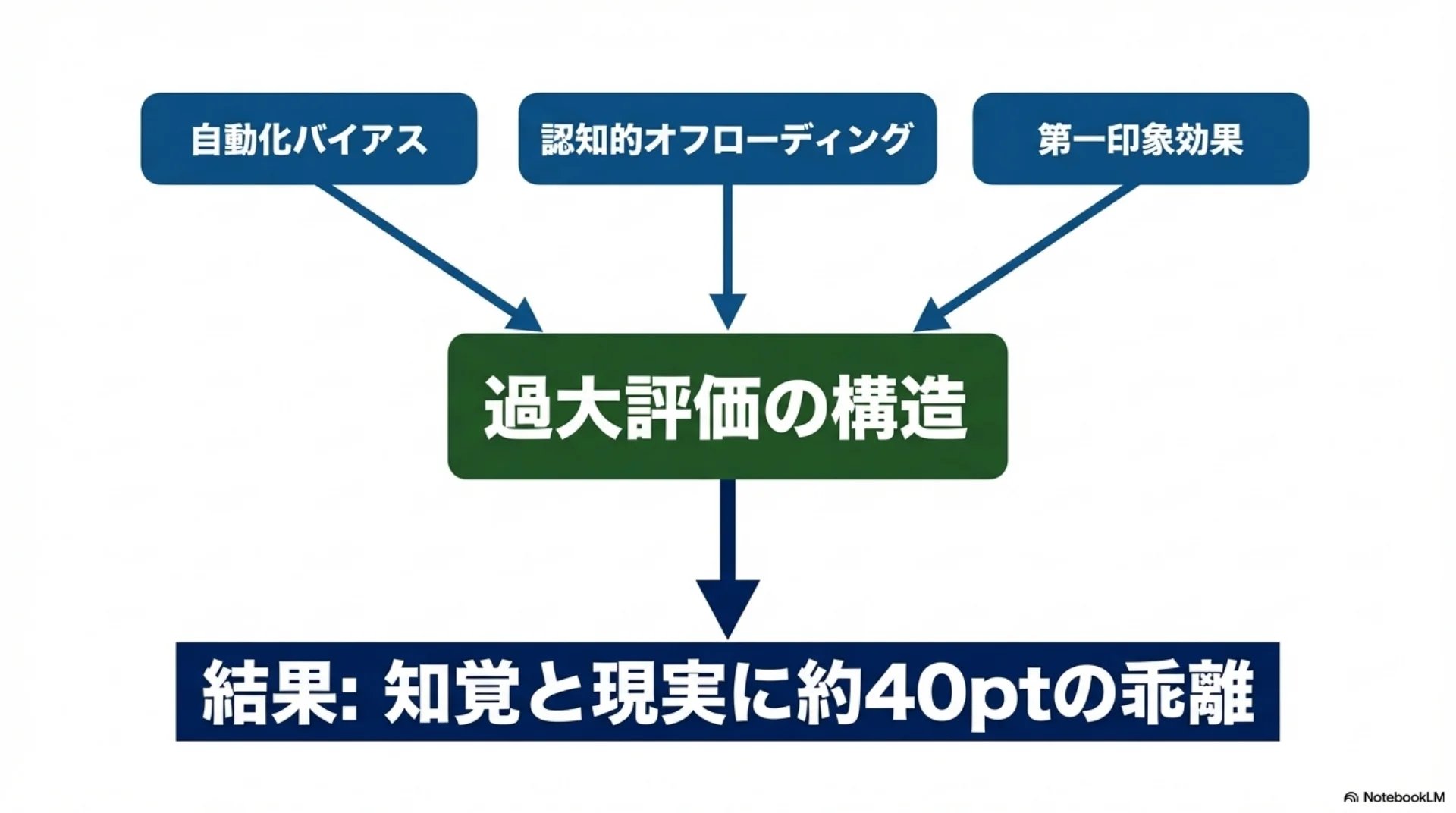
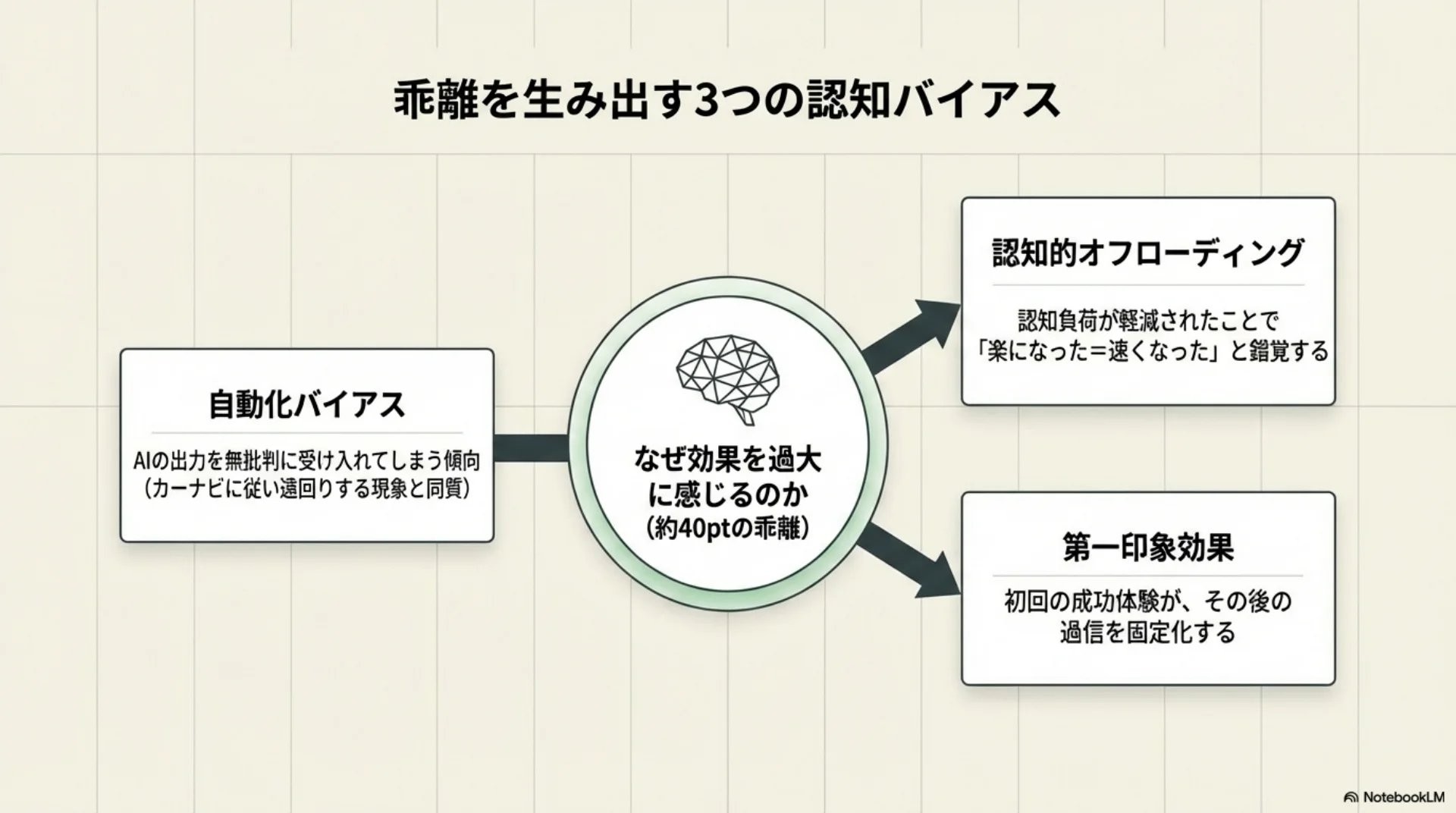
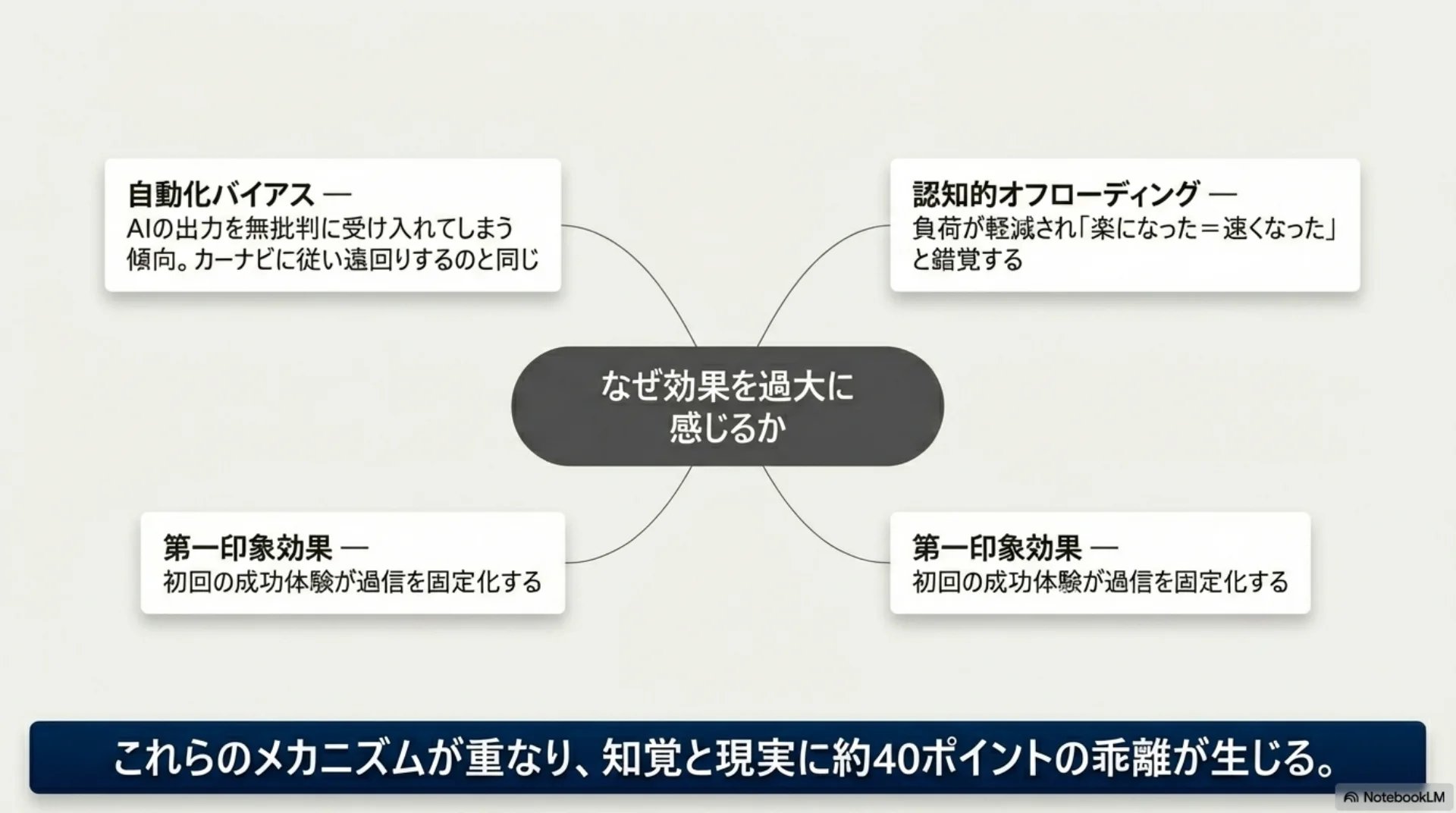
スライド9: ハルシネーションの原理的限界




スライド10: 完全自動化からハイブリッド回帰
スライド11: 精度比較(病理診断)
スライド12: 5変数モデル
スライド13: 構造化度×エラー許容度(2×2マトリクス)
スライド14: 5変数がレベルを決定する仕組み
図解の指示方法
NotebookLM にどうやって「ピラミッドで」「氷山図で」といった図解の種類を指示するか。今回の検証で一番面白かったのはここだ。
明示指定した場合(パターン1〜3)
パターン1〜3 では、カスタムプロンプトで 14 スライド分すべてに図解種別を指定している。実際に使った指定は次のとおり。
| スライド | テーマ | 指定した図解種別 | 日本語での意味 |
|---|---|---|---|
| 1 | タイトル | Hero Layout | 大きなタイトル中央配置 |
| 2 | 核心メッセージ | Quote Focus, large bold typography | 引用を大きく見せる |
| 3 | 適性スペクトラムの5段階 | Hierarchical Pyramid, 5 layers, gradient green-to-red | 5層ピラミッド図 |
| 4 | 自動化向きと人間中心の対比 | Split-Screen Comparison, left=green, right=orange | 左右分割の比較図 |
| 5 | セクションタイトル | Hero Layout | 大きなタイトル中央配置 |
| 6 | 地味な反復処理のROIが高い理由 | Hub & Spoke diagram | 中心から放射する図 |
| 7 | AI生産性効果の実態 | Iceberg Diagram, clear waterline division | 氷山図(水面上/下) |
| 8 | 認知バイアスの構造 | Hub & Spoke diagram | 中心から放射する図 |
| 9 | ハルシネーションの原理的限界 | Quote Focus, large bold typography | 引用を大きく見せる |
| 10 | 完全自動化からハイブリッド回帰 | Circular Diagram, clockwise arrows, 4 segments | 循環図(4段階) |
| 11 | 精度比較(病理診断) | Horizontal Bar Chart, highlight top item | 横棒グラフ |
| 12 | 5変数モデル | Hub & Spoke diagram with central concept | 中心から放射する図 |
| 13 | 構造化度×エラー許容度 | 2x2 Matrix Grid with labeled quadrants | 四象限マトリクス |
| 14 | 5変数がレベルを決定する仕組み | Anatomy Breakdown, labeled components | 要素分解図 |
NotebookLM はこの指示にかなり忠実に従い、指定した図解種別がほぼ狙い通りに生成される。
指定しない場合(パターン4)
パターン4 ではレイアウト種別の指定を一切入れず、枚数・スライド分割方法・トーン・フォーマットだけを指示している。NotebookLM は台本の内容から図解を自動判断する。
たとえば スライド13(構造化度×エラー許容度)は指定なしでも四象限マトリクスになり、しかも記述が簡潔で「例:」のように端的に書かれるので読みやすい。スライド7(AI 生産性効果の実態)は「40ポイントの乖離」をグラフで視覚化する構成になり、核心メッセージが一目で伝わる。
興味深いのは、人間が選んだ図解種別よりも NotebookLM の自動判断の方が適切だったケースがある こと。たとえば スライド3 ではパターン1〜3 で「Hierarchical Pyramid」を指定していたが、5段階の分類は各レベルの量的な大小を含まないスペクトラムであり、ピラミッドが暗示する「底辺ほど多い/頂点ほど少ない」は概念と合わない。指定しなかった パターン4 のスライド3 は横並びの表現を選んでおり、こちらの方が概念に忠実だ。スライド6 も、「Hub & Spoke」に当てはめるよりパターン4 のようなリスト形式に図解を組み合わせた自由な構成の方が分かりやすい。
つまり 図解種別の判断自体を NotebookLM に任せた方が、結果的に内容に合った表現が出やすい。人間が事前に図解を選ぶには図解の知識が必要だし、知識があっても内容との相性を見誤ることがある。さらに、図解種別を正しく選べたとしても、文字の大きさ・余白・配置のバランスまで意図通りに伝えるのは難しく、「考察」で後述するような指示用ワードがそのままスライドに出る問題も起きる。NotebookLM は内容理解・図解選択・レイアウト調整を一体で行えるため、手間と品質のバランスではこの判断を丸ごと任せるのが良い選択だった。
明示指定するときのコツ
指示は 具体的なレイアウト名を英語で書く のが効果的だった。「分かりやすい図にして」のような漠然とした表現だと解釈がブレる。以下のような用語は NotebookLM がよく解釈してくれる。
Hierarchical Pyramid(ピラミッド)Iceberg Diagram(氷山図)Hub & Spoke diagram(ハブ&スポーク図)2x2 Matrix Grid(2×2マトリクス)Horizontal Bar Chart(横棒グラフ)Circular Diagram(循環図)Split-Screen Comparison(分割比較)Anatomy Breakdown(分解図)Quote Focus, large bold typography(引用を大きく見せるレイアウト)Hero Layout(タイトルを大きく中央に置くレイアウト)
考察
スライドの枚数と内容を指示通りに作れる
全パターンに共通する発見。NotebookLM は「何枚のスライドに、どの内容を載せるか」を指示通りに守る。Generate EXACTLY 14 slides. と明示すれば正確に 14 枚を出すし、台本の ## スライドN: マーカーに対応させて「スライド N に対応するスライドを 1 枚ずつ作って」と指示すれば、各スライドの中身が台本の対応セクションと一致する。
これは AI スライド生成ツールとしては地味だが大きなポイントで、「AI に任せたら枚数が勝手に増減する」「似たような内容のスライドがダブる」といった破綻が起きない。動画用の台本を ## スライドN: で区切っておけば、そのまま狙い通りの枚数・構成でスライドが返ってくる。この再現性が保証されているからこそ、パターン4 のような「台本ベースで自動生成」という運用が成り立つ。
装飾制限は表現を硬くする
パターン1(装飾制限あり)とパターン2(装飾制限なし)を見比べると、装飾制限は表現を硬くしていた。パターン1 はフォントや色の変化が少なく整列した箇条書きに寄りがちで、パターン2・3・4 は背景色・グラデーション・強調枠・色使いが豊かで内容の重要度が一目で分かる。図解を前提とするスライドで特に差が顕著だった。
統一感を最優先する場面なら装飾制限にも意味はあるが、大抵の場合はトーンだけ指示する方が表現の幅が広がって結果的に見やすくなる。
ソースを詳しく書くほど意図通りになるとは限らない
パターン1〜3 はスライドの内容を箇条書きで詳しく書き込む方式だが、詳しく書けば理想のスライドになるわけではなかった。
- 文字サイズや余白が想像と違う。同じテキスト量でも NotebookLM の配置次第で予想外に詰まったり間延びしたりする
- 指示用のワードがスライドにそのまま出る。たとえば スライド13 では「左上(低・高)」のように図解の配置を指示するために書いた文字列がスライド本文に表示されてしまう
- 全体的に「こちらの意図を AI が正しくくみ取ってくれない」場面が多い。頭の中にある完成イメージと、NotebookLM の出力との間にギャップが生じやすい
ソースやプロンプトを最適化すれば改善できる可能性はあるが、14 スライド分を個別に調整するのはかなりの手間になる。パターン4 では NotebookLM が要約と構成を自動判断するため、こうした微調整の手間がほとんど発生しなかった。
思い通りに制御できること自体の価値
パターン4 を推してきたが、パターン1〜3 の「指示通りに出す」力は過小評価したくない。一般に画像生成 AI に思い通りの画像を作らせるのは難易度が高いとされるが、NotebookLM はスライド十数枚を一度に、指定した枚数・内容・図解種別でかなり正確に生成できる。これは AI ツールとしてかなり優秀な特性で、プロンプトを作り込む労力を惜しまない場面ではパターン1〜3 の方が向いている。
おわりに
今回の検証から一般化して言えそうなことを 3 つ。
- 図解種別の判断は NotebookLM に任せるのも手。人間が事前に選ぶと内容との相性を見誤ることがある。任せた方が手間と品質のバランスが良い場合が多い
- 否定形の指示(
NO xxx)はコストの割に効果が薄い。ポジティブなトーン指定(Professional, calm, data-drivenなど)の方が効く - 明示指定するなら具体的なレイアウト名の英語(
Hierarchical Pyramid,Iceberg Diagramなど)を使う。漠然とした指示では安定しない
検証に使った元動画のテーマは「AI自動化はどこまで任せるべきか〜適性スペクトラムの考え方〜」。動画本体は別途公開予定。